
화웨이가 자체 개발한 Ascend(쿤펑, 昇腾) AI 칩과 Pangu Ultra MoE 대모델을 통해 GPU 없이도 1만억 개 매개변수에 준하는 수준의 대모델을 성공적으로 훈련시키는 전체 기술 과정을 최초로 공개했다. 이번 발표는 중국 국산 AI 생태계의 자주적 기술 혁신 능력을 보여주는 중요한 이정표로 평가된다.

2초 만에 고등수학 문제 해결하는 놀라운 성능
화웨이가 공개한 Pangu Ultra MoE 모델은 단 2초 만에 고등수학 문제를 완전히 이해하고 해결하는 놀라운 성능을 보여준다. 이는 7,180억 개의 매개변수를 가진 대규모 MoE(Mixture of Experts) 아키텍처를 기반으로 하며, 전체 훈련 과정에서 GPU를 전혀 사용하지 않고 순수 국산 기술 만으로 구현된 점이 특히 주목 받고 있다.
이번 성과의 핵심은 화웨이의 Ascend Atlas 800T A2 훈련 클러스터와 자체 개발 대모델의 조합이다. 사전 훈련 단계에서 1만 카드 클러스터의 MFU(Model FLOPs Utilization)를 41%까지 끌어올렸으며, 후 훈련 단계에서는 단일 CloudMatrix 384 슈퍼노드에서 35K Tokens/s의 처리량을 달성했다.
6가지 핵심 기술 도전 과제 해결
화웨이는 이번 기술 보고서에서 대규모 MoE 모델 훈련의 6가지 주요 도전과제를 체계적으로 분석하고 해결책을 제시했다.
첫째, 병렬 전략 구성의 어려움
데이터 병렬, 텐서 병렬, 전문가 병렬, 파이프라인 병렬, 시퀀스 병렬 등 다양한 전략의 조합 선택과 희소 활성화로 인한 부하 불균형 요인으로 인해 최적의 병렬 구성 방안을 찾기 어려웠다.
둘째, All-to-All 통신 병목 현상
전문가 병렬 아키텍처는 대규모 토큰 라우팅 교환이 필요해 대량의 네트워크 대역폭을 차지하고 계산 자원의 장시간 유휴 대기를 야기한다.
셋째, 시스템 부하 분포 불균형 문제
어텐션 메커니즘의 시퀀스 길이 차이부터 전문가 활성화 빈도의 불균형, 파이프라인 병렬의 각 단계별 부하 분배 문제까지 다층적 불균형이 전체 클러스터 성능을 저하시켰다.
넷째, 운영자 스케줄링 오버헤드 문제
동적 라우팅 메커니즘은 다수의 고주파 소규모 운영자 작업을 도입하여 시스템 스케줄링 부담을 증가시키고 핵심 행렬 계산의 비중을 감소시켜 NPU의 효과적인 활용에 상당한 영향을 미친다.
다섯째, 복잡한 교육 과정 관리
강화 학습 이후의 훈련에는 여러 모델 인스턴스와 다양한 훈련 작업이 포함되며, 여기에는 MoE 대규모 모델의 훈련 및 추론 단계가 포함된다. 전체 프로세스의 복잡성으로 인해 리소스 할당 및 시스템 일정에 큰 어려움이 발생한다.
여섯째, 제한된 확장성|
강화 학습 과정에서 학습과 추론 단계 사이의 매개변수 리매핑 메커니즘과 다양한 컴퓨팅 작업 간의 복잡한 데이터 통신 과정은 대규모 학습 후 배포를 제한하는 주요 병목 현상이 되고 있다.
3단계 핵심 기술 혁신으로 돌파구 마련
화웨이는 이러한 도전과제를 해결하기 위해 3단계 핵심 기술 혁신을 통한 종합적 해결책을 제시했다.
1단계: 훈련 클러스터 이용률 향상
초대규모 훈련 클러스터의 효율적 배치가 사전훈련 시스템 성능 향상의 핵심이다. 화웨이 팀은 모델링 시뮬레이션 기반의 지능형 병렬 최적화를 통해 원래 대량의 인공 시행착오가 필요했던 병렬 전략 선택 문제를 정확한 자동화 검색 과정으로 전환했다.
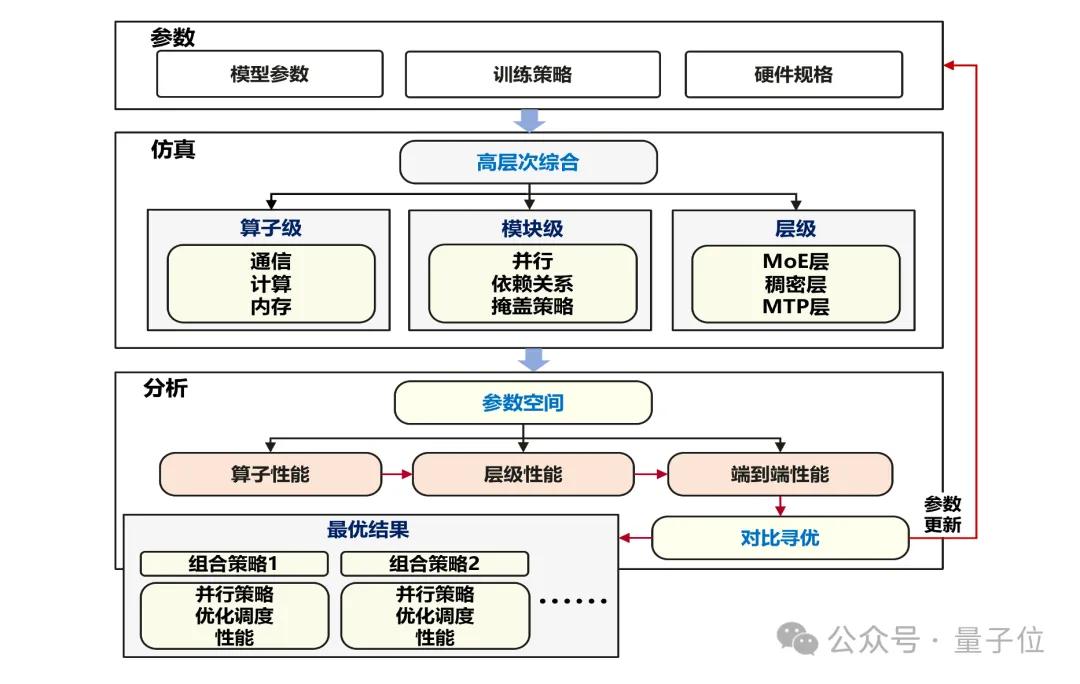
Ascend 800T A2 훈련 클러스터의 하드웨어 특성과 제약 조건을 바탕으로 Pangu Ultra MoE 718B 모델의 최적 배치 구성을 확정했다: 16-way 파이프라인 병렬, 8-way 텐서 병렬, 32-way 전문가 병렬, 2-way 가상 파이프라인 병렬을 통해 Ascend 아키텍처와의 깊이 있는 적응 최적화를 실현했다.
또한 Adaptive Pipe 전후방 계산 은닉 기술을 통해 병렬 확장의 통신 병목 문제를 해결했다. Ascend 네트워크 토폴로지에 적응하는 계층화 All-to-All 통신 중복 제거 메커니즘과 세밀한 전후방 계산 중첩 편성을 결합해 대규모 MoE 훈련의 전문가 병렬 통신 오버헤드를 거의 0에 가깝게(<2%) 줄였다.
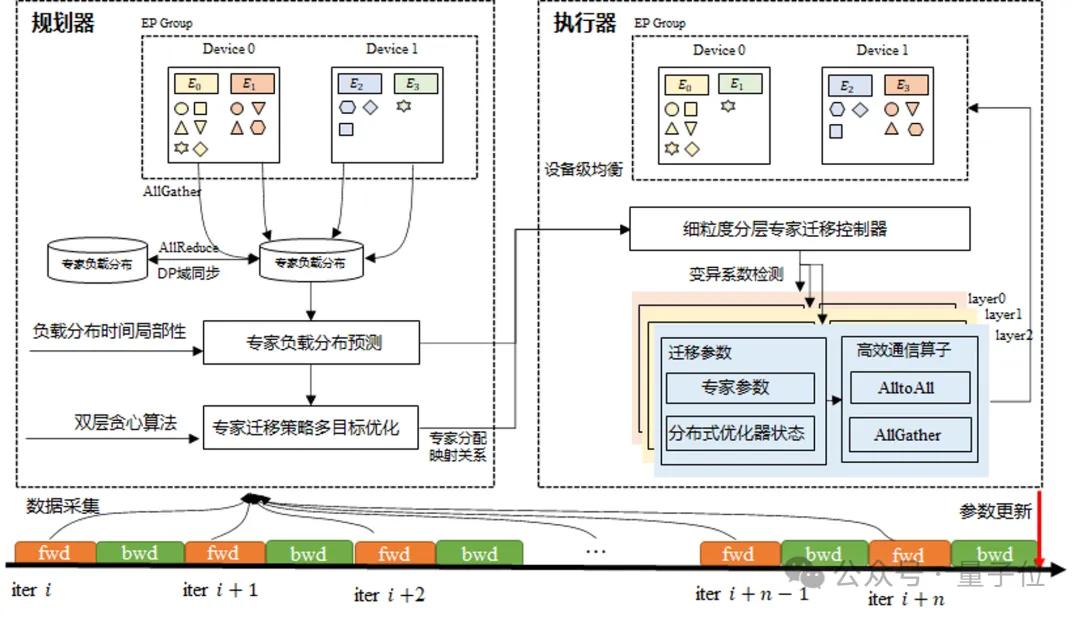
2단계: Ascend 단일 노드 산력 완전 해방
화웨이 팀은 Ascend 아키텍처 깊이 적응 훈련 연산자 가속을 중심으로 Host 자원 병목 완화와 메모리 최적화 전략의 이중 수단을 통해 마이크로 배치 처리 규모(MBS)를 기존의 2배로 향상시켰다.
대모델 훈련 계산 과정에서 FlashAttention, MatMul, Permute/Unpermute 등 벡터 연산 연산자의 실행 시간이 연산자 총 계산 소요시간의 4분의 3 이상을 차지한다. 이러한 핵심 연산자 유형에 대해 화웨이 팀은 Ascend 마이크로아키텍처 특성을 충분히 활용해 연산자 파이프라인 배치 최적화와 수학적 등가 중복 계산 제거 등 핵심 기술을 통해 훈련 연산자 성능을 크게 향상시켰다.
3단계: 고성능 확장 가능한 RL 후훈련 기술 최초 공개
화웨이 팀은 강화학습 훈련의 이종 모델과 멀티태스크 시나리오로 인한 자원 이용률 저하 문제를 해결하기 위해 RL Fusion 훈련추론 공유카드 기술을 제안했다. 이 기술은 훈련추론 공유카드, 전체 공유카드 등 다양한 유연한 배치 모드를 지원하며, 추론 단계 자원 스케줄링의 정밀화 제어 가능 관리를 실현한다.
텐서 병렬(TP), 데이터 병렬(DP), 전문가 병렬(EP), 파이프라인 병렬(PP) 등 다차원 병렬 전략의 동적 원활한 전환을 지원하며, 초 단위 시간 내에 훈련추론 상태 전환을 완료해 최종적으로 RL 후훈련 클러스터 이용률 2배 향상이라는 뚜렷한 성과를 달성했다.
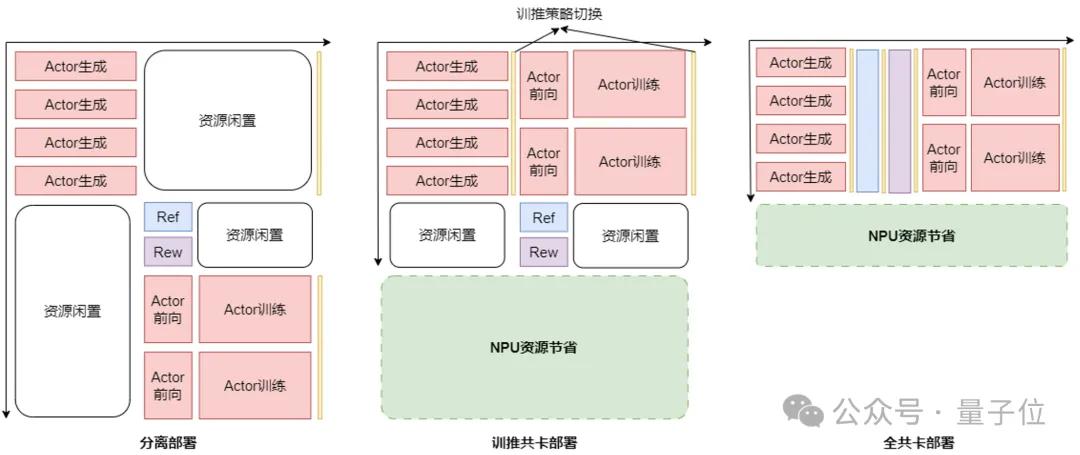
완전 자주 제어 가능한 국산 AI 생태계 구축
이번 화웨이의 기술 공개는 단순한 성능 향상을 넘어 국산 산력과 국산 모델의 전체 과정 자주 제어 가능한 훈련 폐루프를 실현했다는 점에서 특별한 의미를 갖는다. Pangu Ultra MoE 모델은 61층 Transformer 구조를 포함하며, 처음 3층은 조밀층, 나머지 58층은 MoE층으로 구성된다.
모델 은닉층 차원은 7,680에 달하며, 256개의 라우팅 전문가와 1개의 공유 전문가를 배치했고, 전문가 은닉층 차원은 2,048이다. 사전훈련 단계에서 6K-10K 카드의 Ascend 800T A2 클러스터를 사용해 Pangu Ultra MoE를 훈련 시켰으며, 시퀀스 길이 8K, 만 카드 훈련 클러스터 조건에서 모델 산력 이용률(MFU)이 41%라는 새로운 기록을 달성했다.
미래 확장 가능성과 기술적 파급효과
화웨이는 이번 훈련 시스템이 강력한 범용성을 갖고 있어 더 큰 규모의 매개변수 모델과 더 큰 규모의 카드 수 클러스터로 효율적으로 확장 가능하다고 밝혔다. 특히 Ascend CloudMatrix 384 슈퍼노드의 고속 상호연결 특성과 결합하면 훈련 클러스터 MFU 50% 이상 지원이 가능할 것으로 예상된다고 전했다.
RL 후훈련 단계에서는 Pangu Ultra MoE Ascend CloudMatrix 384 슈퍼노드 클러스터의 후훈련에서 훈련추론 혼합 병렬 전략을 채택하고 비동기 RL 알고리즘과 훈련 프레임워크 시스템의 협동 혁신을 결합해 슈퍼노드당 35K Tokens/s의 높은 처리량 능력을 실현했다.
이는 4K 카드 이상의 클러스터로 효율적 확장을 지원하며, 이러한 효율성은 2초마다 고등수학 문제 하나를 완전히 이해할 수 있는 수준으로, Ascend 슈퍼노드 처리량의 새로운 돌파를 실현했다.
이번 화웨이의 기술 공개는 중국의 AI 기술 자주 혁신 능력을 보여주는 동시에, 글로벌 AI 생태계에서 GPU 의존도를 낮추는 새로운 기술 경로를 제시했다는 점에서 업계의 큰 주목을 받고 있다.




