
강화학습(Reinforcement Learning) 분야에 새로운 혁신이 나타났다. 칭화대학교 교차정보학원과 앤트 기술연구원의 연합팀이 전면 비동기 강화학습 훈련 시스템 ‘AReaL-boba²’를 오픈소스로 공개했다고 발표했다. 이 시스템은 기존 대비 177%의 효율성 향상을 달성하며, 8B 및 14B 모델에서 동급 최고 성능(SOTA)을 기록했다.

강화학습이 AI 발전의 새로운 동력으로 부상
최근 AI 업계에서는 강화학습에 대한 관심이 급증하고 있다. OpenAI의 o1 모델이 대규모 언어모델에서 강화학습의 엄청난 잠재력을 입증한 데 이어, DeepSeek-R1이 이 기술의 성능과 비용 효율성을 최적화하면서 강화학습은 AI의 차세대 지능 수준 향상을 이끄는 핵심 엔진으로 자리 잡고 있다.
학계에서도 강화학습의 가치를 높이 평가하고 있다. 올해 3월 5일, 이 기술에 선구적인 공헌을 한 앤드류 바토(Andrew Barto)와 리처드 서튼(Richard Sutton)이 튜링상을 수상하며 강화학습의 중요성을 다시 한번 입증했다.
AReaL-boba²의 핵심 혁신: 완전 비동기 훈련
AReaL-boba²의 가장 큰 특징은 모델 생성과 훈련을 완전히 분리한 것이다. 이를 통해 중단 없는 스트리밍 데이터 생성과 병렬 훈련을 동시에 구현했다. 효과는 그대로 유지하면서 훈련 속도를 이전 버전 대비 2.77배 향상시켰다.
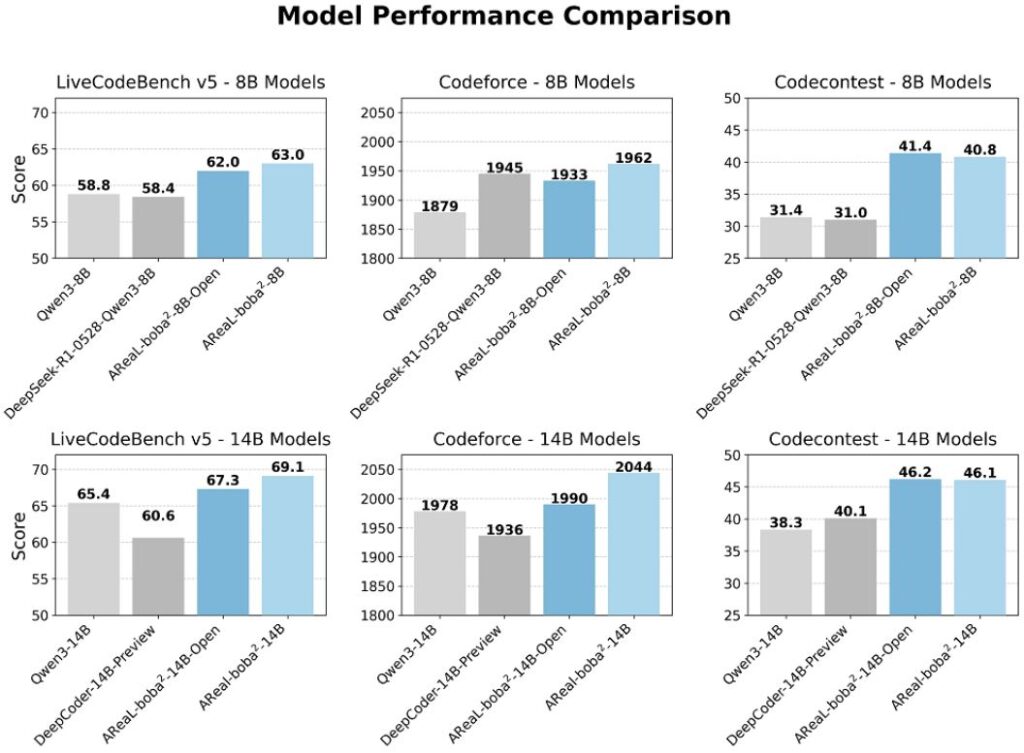
연구팀은 Qwen3 시리즈 모델을 기반으로 AReaL-boba²를 사용해 강화학습 훈련을 진행했으며, 관련 모델을 오픈소스로 공개했다. 다양한 프로그래밍 분야 권위 벤치마크 테스트에서 강화학습을 거친 8B 및 14B 파라미터 모델이 동급 최고 성능을 달성했다.
기존 강화학습 시스템의 한계와 해결책
기존 강화학습 알고리즘의 생성과 훈련 단계는 엄격한 시간 순서에 따라 결합되어 있어, 각 훈련 라운드마다 현재 라운드의 모든 샘플 생성 작업이 완료될 때까지 기다려야 하는 동기식 강화학습 방식을 사용했다.
대형 추론 모델의 경우, 프롬프트 내용에 따라 출력 길이가 크게 달라져 일부 샘플은 빠르게 생성되지만 다른 샘플들은 매우 느리게 생성되어 하드웨어 리소스의 유휴 상태와 낭비를 초래했다.
또한 주류 강화학습 알고리즘(PPO, GRPO 등)은 ‘최신 정책 데이터’에 대한 의존성으로 인해 시스템 설계의 복잡성을 가중시켰다. 이러한 알고리즘들은 훈련 샘플이 반드시 현재 모델 버전에서 생성되어야 한다고 요구하여 훈련 데이터의 우수한 ‘정책 일관성’을 보장해야 했다.
4대 핵심 구성요소로 구현한 전면 비동기 시스템
AReaL-boba²는 고효율 대규모 언어 모델 강화학습 훈련을 위해 설계된 비동기 강화학습 시스템으로, 네 가지 주요 구성 요소로 이루어져 있다.
첫째, ‘중단 가능한 궤적 생성기(Interruptible Rollout Worker)’는 모델 출력 생성을 담당하며, 생성과 동시에 새로운 모델 가중치를 수신할 수 있다. 업데이트 요청을 받으면 즉시 현재 생성을 중단하고 기존 캐시를 삭제한 후 새로운 가중치를 로드하여 생성을 계속한다.
둘째, ‘보상 서비스(Reward Service)’는 생성 콘텐츠의 품질을 평가하는 역할을 한다. 예를 들어 코드 작업에서는 코드를 추출하고 테스트를 실행하여 코드의 정확성을 확인한다.
셋째, ‘훈련기(Trainer Workers)’는 이전에 생성된 데이터에서 지속적으로 샘플링하여 강화학습 알고리즘을 실행해 모델을 업데이트하고 새로운 모델 파라미터를 저장한다.
넷째, ‘생성 제어기(Rollout Controller)’는 전체 시스템의 두뇌 역할을 한다. 데이터 셋에서 데이터를 읽어 생성기가 콘텐츠를 생성하도록 하고, 콘텐츠를 보상 서비스에 전송해 점수를 매기며, 점수가 매겨진 콘텐츠를 버퍼에 저장해 훈련기의 훈련을 기다린다.
알고리즘 혁신으로 안정성과 효율성 동시 확보
비동기 강화학습 시스템에서는 서로 다른 훈련 배치의 데이터가 구 버전 모델에서 나올 수 있어 훈련 데이터와 현재 모델 간의 불일치가 발생할 수 있다. 이러한 데이터 진부화(Data Staleness) 문제를 해결하기 위해 AReaL-boba²팀은 여러 혁신적인 알고리즘을 개발했다.
연구팀은 먼저 최대 허용 지연값 ‘η’를 도입하여 생성 데이터에 사용된 정책(모델) 버전과 현재 훈련 정책(모델) 버전 간의 차이를 제한했다. η는 훈련 데이터의 진부화 정도를 효과적으로 제어한다.
더 나아가 AReaL-boba²는 분리된 버전의 PPO(Proximal Policy Optimization) 알고리즘을 채택했다. 이 알고리즘은 데이터를 생성하는 행동 정책(구 정책일 가능성)과 현재 모델을 제약하는 근접 정책을 분리하여 처리한다. 전통적인 PPO 알고리즘은 이 두 정책이 동일해야 하지만, 비동기 훈련에서는 현실적이지 않다.
분리된 PPO는 중요도 샘플링을 통해 훈련 시 행동 정책과 근접 정책 간의 차이를 수정하여 훈련의 효과성과 안정성을 보장한다.
뛰어난 성능과 확장성 입증
AReaL-boba²는 알고리즘과 시스템의 협력 설계(co-design)를 통해 완전 비동기 강화학습 훈련을 구현했다. 생성과 훈련이 서로 다른 GPU를 사용하며 완전히 분리되어 있다.
128장의 카드를 사용해 1.5B 모델을 32k 출력 길이, 512 x 16 배치 크기 설정으로 강화학습 훈련할 때, 비동기 방식은 동기 방식 대비 각 훈련 단계 소요 시간을 52% 단축했다.
성능 평가를 위해 연구팀은 DeepSeek-R1 시리즈에서 증류 된 Qwen2 모델을 사용했으며, 1.5B부터 32B까지 다양한 규모를 다루고 여러 방식으로 강화학습 훈련을 진행했다. 훈련 과정에서 512장의 H800 GPU를 사용했으며, 리소스를 최대한 활용하기 위해 장비의 4분의 3을 추론 작업에 할당했다.
실험 결과 AReaL-boba²는 기존 동기식 강화학습 시스템(VeRL, AReaL의 초기 sync 버전 등)과 동등하거나 더 우수한 성능을 보이면서 훈련 속도에서 최대 2.77배의 향상을 달성했다.
확장성 측면에서도 AReaL-boba²는 거의 선형적인 확장 능력을 보여주었다. 장비 수량이 증가함에 따라 훈련 처리량이 거의 비례적으로 증가했다. 반면 기존 동기식 시스템은 대형 모델과 긴 컨텍스트 설정에서 확장성이 좋지 않았고, 심지어 메모리 오버플로우 제한에 직면했다.
Agentic AI 시대를 위한 미래 지향적 시스템
AReaL-boba²의 개발팀은 이 강화학습 시스템을 여러 차례 반복 개발하며 ‘전면 오픈소스, 초고속 훈련, 심층 커스터마이징’ 개발 이념을 지속적으로 견지해왔다. 이번에는 훈련 시스템의 성능 한계를 확장했을 뿐만 아니라 더욱 포괄적인 개발자 지원을 제공했다.
Agentic AI가 점진적으로 복잡한 작업 해결과 자율 의사 결정 시스템 구축의 중요한 경로가 되고 있는 상황에서, AReaL-boba²와 같은 비동기 강화학습 시스템은 다중 라운드, 긴 컨텍스트, 고복잡도의 지능체 작업에 더욱 효율적이고 안정적인 훈련 메커니즘을 제공할 것으로 기대된다.
특히 이 시스템은 오픈소스 코드, 데이터 셋, 스크립트 및 SOTA급 모델 가중치 기반 위에 상세한 튜토리얼과 심층 문서를 새로 추가하여 개발자들이 더욱 편리하게 연구 성과를 사용하고 커스터마이징할 수 있도록 도왔다. 또한 다중 라운드 지능체 강화학습(Multi-Turn Agentic 강화학습) 훈련에 대한 네이티브 지원도 제공한다.
강화학습 기술의 지속적인 발전과 함께 AReaL-boba²와 같은 혁신적인 시스템들이 미래 AI 지능체 개발에 더욱 강력한 기술적 지원을 제공할 것으로 전망된다.
[오픈소스 주소]
https://github.com/inclusionAI/AReaL/
[논문 링크]
https://arxiv.org/pdf/2505.24298
[SOTA 모델 다운로드 링크]
https://huggingface.co/collections/inclusionAI/areal-boba-2-683f0e819ccb7bb2e1b2f2d5




