
알리바바 Qwen이 Qwen3-Embedding과 Qwen3-Reranker 시리즈 모델을 새롭게 공개하며 텍스트 처리 분야에서 새로운 이정표를 세웠다. 특히 Qwen3-Embedding 8B 모델은 MTEB(Massive Text Embedding Benchmark) 다국어 순위에서 70.58점을 기록하며 전 세계 1위를 차지했다.

Qwen3 시리즈 모델의 혁신적 특징
알리바바가 6월 6일 발표한 Qwen3-Embedding과 Qwen3-Reranker는 모두 Qwen3 기반 모델을 바탕으로 훈련되었으며, 텍스트 표현, 검색, 순위 지정 작업에 특화되어 설계되었다. 두 모델은 Apache 2.0 라이선스로 완전 오픈소스로 제공되며, Hugging Face, GitHub, ModelScope를 통해 무료로 상업적 이용이 가능하다.
Qwen3-Embedding 모델은 단일 텍스트 입력을 받아 의미 벡터로 변환하는 기능을 수행한다. 이는 의미 검색, 질의응답 시스템 등의 시나리오에서 활용된다. 반면 Qwen3-Reranker는 텍스트 쌍을 입력받아 단일 타워 구조를 통해 두 텍스트 간의 연관성 점수를 계산하고 출력한다. 이를 통해 다양한 텍스트 검색 시나리오에서 검색 결과의 연관성을 현저히 향상시킬 수 있다.
실제 응용에서는 두 모델이 함께 사용되는 경우가 많다. RAG(Retrieval-Augmented Generation) 시스템에서 Qwen3-Embedding은 초기 검색을 담당하고, Qwen3-Reranker는 후보 결과를 최적화하여 효율성과 정확도를 모두 만족시킨다.

MTEB 벤치마크에서의 압도적 성능
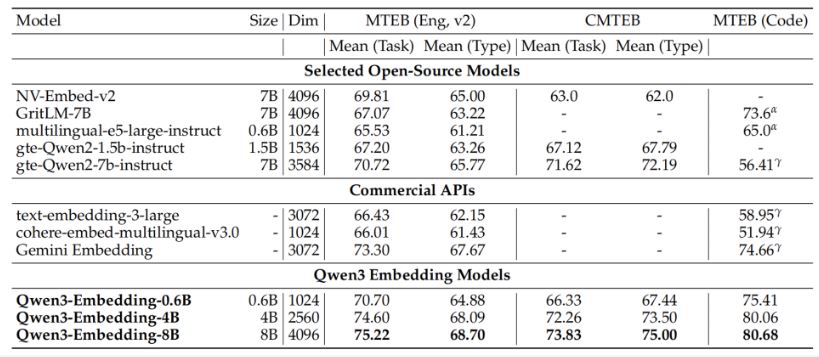
Qwen3-Embedding 8B 모델이 달성한 MTEB 다국어 순위 1위는 매우 의미 있는 성과다. MTEB는 현재 전 세계적으로 공인받는 텍스트 임베딩 모델 평가 기준으로, 검색, 클러스터링, 분류 등 7가지 주요 시나리오를 통합하여 벡터 모델의 의미 표현 능력을 체계적으로 평가한다.

특히 주목할 점은 Qwen3-Embedding이 Google Gemini-Embedding과 같은 상용 모델들을 제치고 1위를 차지했다는 것이다. 코드 검색(MTEB-Code) 작업에서도 검색 정확도 1위를 기록하며 다양한 분야에서의 우수성을 입증했다.

다국어 검색 작업에서 Qwen3-Embedding 8B 모델은 69.02점을 기록했으며, 중국어 검색에서는 77.45점, 영어 검색에서는 69.76점을 달성했다. 이는 기존의 BM25, ColBERT 등 전통적인 기준선 모델들을 크게 앞서는 성능이다.
119개 언어 지원과 32K 토큰 처리 능력
Qwen3 시리즈 모델의 가장 인상적인 특징 중 하나는 119개의 자연어와 Python, Java 등의 프로그래밍 언어를 지원한다는 점이다. 또한 32K 토큰의 긴 텍스트 처리 능력을 제공하여 법률 문서, 과학 논문 등의 장문 처리에 최적화되었다.
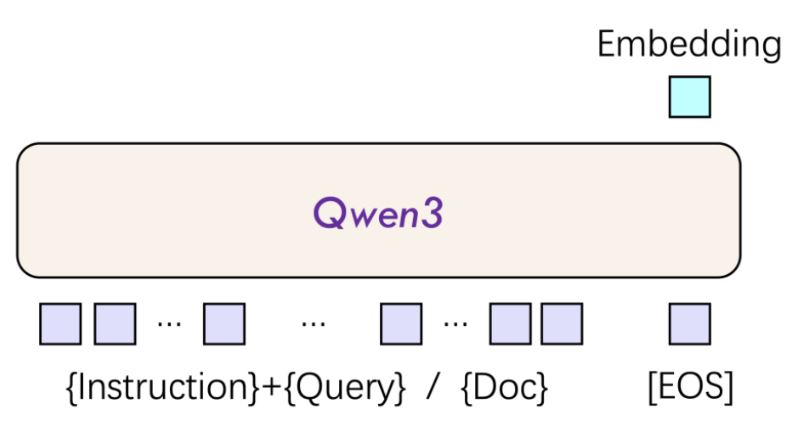
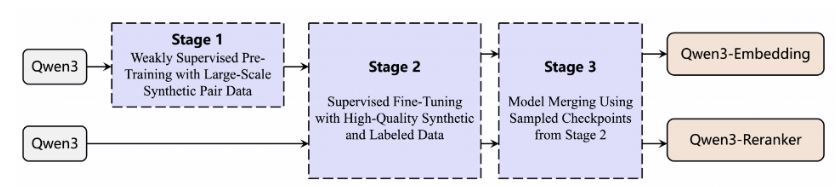
Qwen3-Embedding 모델은 혁신적인 이중 인코더 아키텍처를 채택하여 쿼리 텍스트와 문서 내용을 독립적으로 처리할 수 있다. 이를 통해 고정밀도 의미 벡터를 생성한다. 모델은 3단계 훈련 프레임워크를 따른다: 첫 번째 단계에서는 36조 토큰의 다국어 데이터를 기반으로 약한 지도 사전 훈련을 수행하고, 두 번째 단계에서는 MS MARCO 라벨링 데이터를 융합하여 지도 학습 미세 조정을 진행하며, 마지막으로 모델 융합 기술을 통해 일반화 성능을 향상시킨다.
추론 층면에서 Qwen3-Embedding 모델은 혁신적으로 사용자 정의 명령 템플릿을 지원하여 특정 작업의 성능을 3%-5% 향상시킬 수 있다. 이는 OpenAI의 text-embedding과 같은 경쟁 제품이 고정 차원만 지원하는 것과 대비되는 유연한 설계다.
Qwen3-Reranker의 차별화된 순위 지정 능력
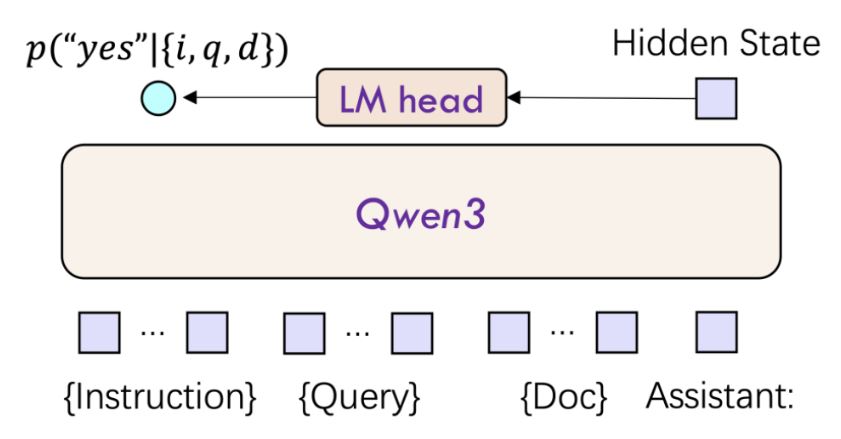
Qwen3-Reranker 시리즈는 검색 및 추천 시스템의 연관성 순위 지정 능력 향상에 특화된 모델로, 0.6B, 4B, 8B의 세 가지 매개변수 규모를 제공한다. 이 모델은 단일 타워 상호작용 구조를 채택하여 사용자 쿼리와 후보 문서를 연결하여 입력하고, 쿼리-문서 상호작용 특징을 동적으로 계산하여 연관성 점수를 출력한다.
mMARCO 다국어 검색에서 Qwen3-Reranker는 MRR@10에서 0.42를 달성하여 업계 표준을 넘어섰다. 특히 100개 문서 순위 지정 지연 시간을 A100에서 80ms 이내로 압축하여 실시간 처리 성능을 크게 개선했다.
장문 문서 시나리오를 위해 Qwen3-Reranker 모델은 RoPE 위치 인코딩과 이중 블록 어텐션(Dual Chunk Attention) 메커니즘을 통합하여 장거리 정보 손실을 효과적으로 방지하고 32K 컨텍스트 내에서 의미 일관성을 보장한다.
세 가지 규모 별 모델 구성과 특징
Qwen3-Reranker 0.6B 모델은 초소형 모델로 엣지 디바이스 배포에 적합하다. 32K의 컨텍스트 길이를 가지며 Transformer 기반 아키텍처를 채택한다. RMSNorm을 통해 레이어 입력을 정규화하여 훈련 안정성을 확보한다.
Qwen3-Reranker 4B 모델은 4B 매개변수로 Qwen2.5-72B-Instruct와 견줄 만한 성능을 보인다. AIME25(미국 수학 초청 대회) 평가에서 81.5점을 기록하여 오픈소스 모델 기록을 갱신했으며, 강력한 수학적 추론 능력을 보여준다.
Qwen3-Reranker 8B 모델은 8B 매개변수로 표준 구성에서 32,768개 토큰의 컨텍스트 길이를 가진다. 다국어 검색 작업에서 69.02점을 달성하여 bge-reranker-large 등 오픈소스 경쟁 제품을 능가했다.
산업 응용과 기술적 파급효과
Qwen3 시리즈 모델의 공개는 고정밀도 검색 기술의 대중화를 추진할 것으로 예상된다. 기업 지식베이스 질의응답 정확도가 40% 향상되고, 인력 비용이 대폭 절감될 전망이다. 크로스보더 전자상거래에서는 119개 언어 상품 정밀 검색을 실현하여 오검출률이 35% 감소할 것으로 기대된다.
과학연구 및 법률 분야에서는 장문 문서 검색 효율성이 90%를 돌파하여 정보 추출 속도가 크게 향상될 것이다. 알리바바의 오픈소스 전략은 개발자 생태계를 활성화시키며, Hugging Face를 통한 빠른 산업 모델 미세 조정과 알리클라우드 API의 5줄 코드 접속 지원으로 기술 진입 장벽을 크게 낮췄다.
이는 텍스트 검색을 기존 ‘키워드 매칭’에서 ‘의미 이해+동적 상호작용’으로 업그레이드하여 AI Agent와 멀티모달 애플리케이션의 기반을 마련하는 의미가 있다.
맞춤형 최적화와 실용적 배포
Qwen3 시리즈 모델은 작업 명령 미세 조정을 지원하여 개발자가 사용자 정의 명령을 통해 특정 도메인 성능을 최적화할 수 있다. 실측 결과 순위 지정 정확도가 3%-5% 향상되는 것으로 나타났다. 이는 ColBERT와 같은 경쟁 제품에는 없는 기능이다.
알리바바의 기술 보고서에서는 실제 검색 시나리오에서 구체적인 작업, 언어, 시나리오에 따라 명령 템플릿을 설계할 것을 권장한다고 특별히 언급했다. 그렇지 않으면 효과에 영향을 미칠 수 있다는 점을 강조했다. 이러한 세부사항은 AI 모델이 ‘범용 일반화’에서 ‘정밀 전용’으로 진화하고 있음을 반영하며, 업계에 새로운 최적화 방향을 제시한다.
Qwen3-Embedding과 Qwen3-Reranker는 ‘다국어+장문+맞춤형’ 삼위일체 설계를 통해 기존 텍스트 처리 모델의 일반화 성능 부족과 높은 비용 문제를 해결했다. 오픈소스 전략은 산업 응용 혁신을 가속화할 것이며, 개발자는 Hugging Face를 기반으로 빠른 미세 조정이 가능하고, 기업은 알리클라우드 API를 통해 즉시 배포할 수 있다.
이번 발표는 알리바바가 텍스트 임베딩 분야에서 경량급부터 고성능까지 전 시나리오 요구사항을 커버하는 기술 포트폴리오를 완성했음을 의미한다. 특히 오픈소스 무료 전략은 중소기업이 제로 비용으로 문서 검색, 지식베이스 클러스터링 등 시스템을 구축할 수 있게 하여, 다국어 텍스트 처리 기술이 보편적 응용 단계로 진입할 가능성을 열었다.
[같이 읽으면 좋은 글]
알리바바 Qwen, 강화학습 훈련 시 20%의 토큰 만으로 더 나은 성능 달성




