
알리바바가 세계 최초로 사고연쇄(Chain of Thought, CoT) 기술을 적용한 AI 음성생성 모델 ‘ThinkSound’를 오픈소스로 공개했다고 7월 1일 발표했다. 이 모델은 AI 생성 비디오에 정확한 배경음과 효과음을 자동으로 매칭시키고, 게임 사운드 이펙트를 실시간으로 생성하는 등 다양한 분야에서 활용될 수 있다.

알리바바 ThinkSound 모델의 핵심 기술과 특징
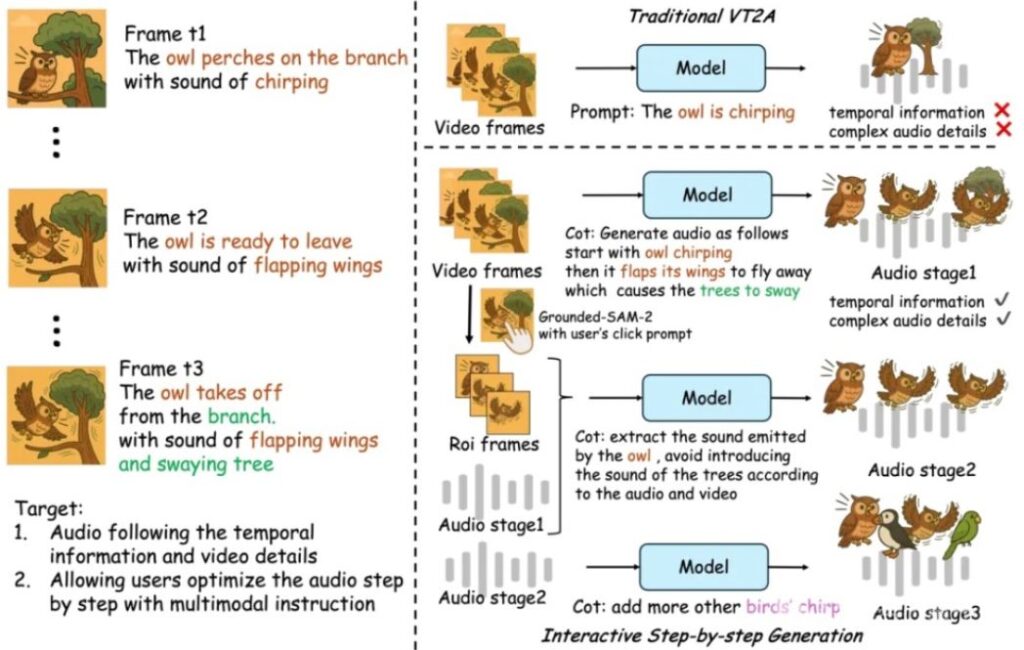
ThinkSound는 알리바바 통의실험실(Tongyi Lab)이 개발한 혁신적인 음성생성 모델로, 전통적인 비디오-오디오 변환(V2A) 기술의 음화불일치 문제를 해결하기 위해 다단계 추론 프레임워크를 도입했다. 이 모델의 가장 큰 특징은 전문 음향 기술자의 작업 과정을 모방한 3단계 추론 시스템이다.
현재 ThinkSound는 세 가지 버전으로 제공된다. ThinkSound-1.3B(13억 매개변수)는 전문급 음향 효과 생성 작업에 최적화되어 있으며, ThinkSound-724M(7.24억 매개변수)은 음향 품질과 계산 효율성의 균형을 맞춘 모델이다. ThinkSound-533M(5.33억 매개변수)은 경량화된 입문용 모델로 기본적인 음향 효과 생성 능력을 제공하면서도 하드웨어 요구사항을 크게 낮췄다.

인간 음향 기술자의 작업 과정을 모방한 3단계 추론
ThinkSound 모델의 혁신성은 전문 음향 기술자의 핵심 작업 로직을 성공적으로 모방한 점에 있다.
첫 번째 단계인 시각 이벤트 분석에서는 비디오 내용을 프레임별로 분석하여 유리 파편 궤적이나 발걸음 이동 속도와 같은 핵심 물리적 사건들을 정확히 식별한다. 동시에 화면 속 객체들의 재질 속성(금속, 목재, 액체 등)을 판단하여 시간 스탬프가 포함된 구조화된 이벤트 및 속성 데이터를 출력한다.
두 번째 단계인 음향 속성 추론에서는 분석된 시각적 특징을 바탕으로 물리학 법칙을 적용하여 매핑 작업을 수행한다. 재질 유형에 따라 소리의 주파수 특성을 추론하고, 금속 재질은 고주파 공명을 생성하며, 운동 강도에 따라 음파 에너지를 계산한다. 또한 밀폐된 방이나 열린 광장과 같은 환경 공간이 음장 반사에 미치는 영향을 시뮬레이션하여 물리적 특성이 정확한 음향 매개변수 매트릭스를 생성한다.
마지막 단계인 시간 동기화 합성에서는 동적 정렬 엔진을 통해 음향 매개변수와 비디오 프레임을 정확히 바인딩한다. 시간 인코더를 활용하여 화면 프레임 건너뛰기나 슬로우 모션 변화를 자동으로 보상하여 음파의 연속성을 보장하고, 계층적 렌더링 기술을 사용하여 기본 음색 레이어, 환경 반사 레이어, 모션 특수효과 레이어를 포함한 음성 스트림을 실시간으로 합성한다.
세계 최초 AudioCoT 데이터셋 구축
전통적인 음성 생성 모델의 ‘블랙박스’ 운영 방식과 설명 가능한 설계 로직 부족 문제를 해결하기 위해, 알리바바 팀은 업계 최초이자 최대 규모의 사고연쇄 주석이 포함된 음성 데이터셋 AudioCoT를 구축했다. 이 데이터셋은 총 2,531.8시간의 음성 및 시각 자료를 통합하여 영화 클립 라이브러리, 고화질 자연 음장 수집, 국제적으로 유명한 전문 음향 효과 라이브러리를 포함한다.
AudioCoT의 핵심 혁신은 사고연쇄 주석 시스템에 있다. 각 데이터는 전문 팀이 완전한 논리 체인을 깊이 주석으로 표시했다. 주석 팀은 시각적 이벤트 분석을 통해 화면의 핵심 트리거 요소를 식별하고, 음향 특성 추론을 통해 소리가 가져야 할 물리적 및 인지적 속성을 추론하며, 음향 효과 합성 전략을 통해 목표 소리를 구현하는 기술적 경로를 명확히 한다.
기존 모델 대비 뛰어난 성능 검증
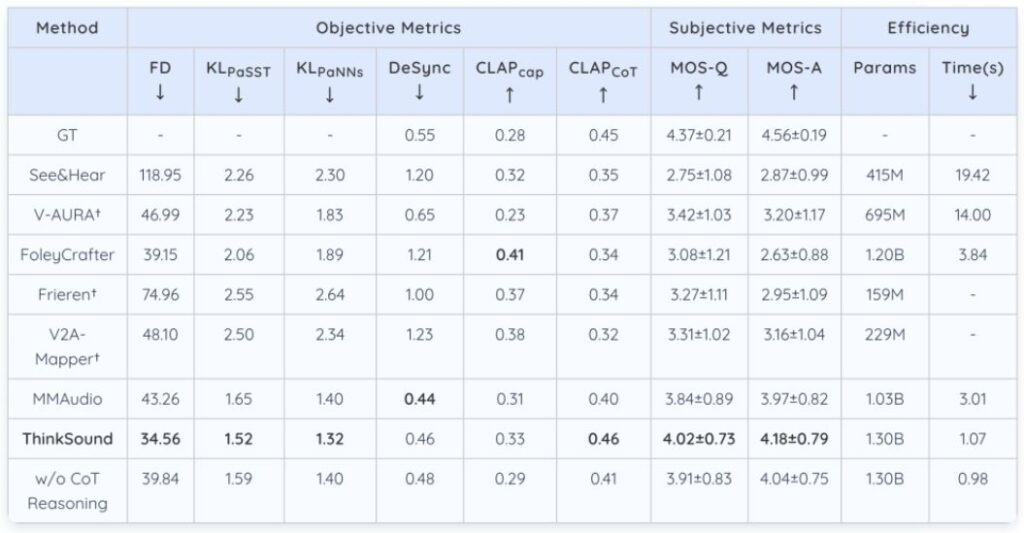
권위 있는 테스트 셋인 VGGSound에서 ThinkSound의 Fréchet 오디오 거리(FD)는 34.56으로 감소했으며, 이는 기존 주류 모델인 MMAudio(43.26)보다 20.1% 향상된 수치다. 시간 동기화 오류율은 단 9.8%로 동기간 대비 37.2% 감소했다. 음성 이벤트 판별 지표인 KLPaSST와 KLPaNNs는 각각 1.52와 1.32를 달성하여 현재 동급 모델 중 최고 성능을 기록했다.
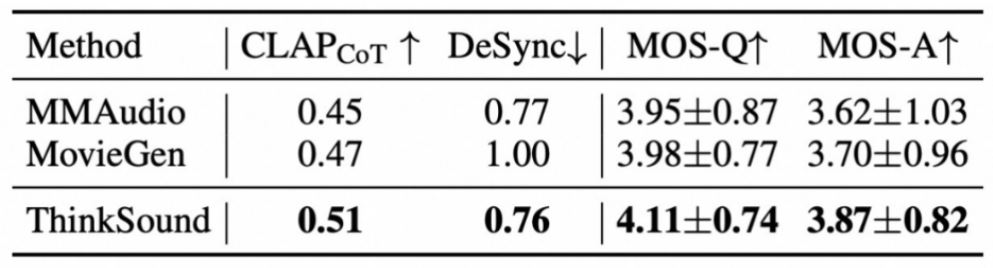
영화 시나리오 테스트 셋인 MovieGen Audio Bench에서 ThinkSound는 메타(Meta)의 Movie Gen Audio 모델을 20% 우위로 크게 앞섰다. 특히 폭발, 금속 마찰 등 복잡한 음향 효과의 시간 동기화 오류율을 37% 감소시켰다. 생물학적 음향 시나리오에서 ThinkSound 모델이 생성한 유아 울음소리 오디오는 표정 동작 변화와 엄격하게 일치하며, 음높이 동적 범위와 호흡 리듬 파동이 유아의 생리적 발성 패턴을 정확히 따른다.
다양한 산업 분야 적용 가능성
ThinkSound 모델은 영화 후반 제작에 직접 적용되어 AI 생성 비디오에 정확한 환경 소음과 폭발 음향 효과를 자동으로 매칭 시킬 수 있다. 게임 개발 분야에서는 비 강도 변화 등 동적 시나리오의 적응형 음향 효과를 실시간으로 생성할 수 있으며, 시각 장애인을 위한 무장애 비디오 제작에서는 화면 설명과 환경 음향 효과를 동시에 생성할 수 있다.
개발자들은 GitHub, Hugging Face, 마텍 커뮤니티를 통해 Apache 2.0 라이선스의 오픈소스 코드를 무료로 호출할 수 있다. 이는 중소 규모 창작자들에게 전문 스튜디오 수준의 음성 제작 능력을 제공하며, 전통적으로 수 시간이 걸리던 수작업 음화 동기화 작업을 분 단위로 압축할 수 있게 한다.
알리바바 음성 기술 생태계 완성
ThinkSound의 출시는 음성 생성이 ‘소리를 낼 수 있는’ 단계에서 ‘화면을 이해하는’ 지능적 단계로 발전했음을 의미한다. 이 기술의 가치는 성능 향상 뿐만 아니라 전문 음향 효과 설계 과정의 표준화와 자동화에 있다. ThinkSound는 알리바바가 이전에 오픈소스로 공개한 CosyVoice 2.0(음성 합성), Qwen2.5-Omni(전면 모달 상호작용)와 함께 기술 매트릭스를 형성하여 음성에서 환경 음향 효과까지 전 시나리오 음성 생성 요구 사항을 포괄한다.
이번 오픈소스 공개로 개발자들은 영화 더빙, 게임 실시간 음향 효과, 무장애 비디오 제작 등 저비용 도구를 구축할 수 있으며, 특히 중소 창작자들에게 전문 작업실에 근접한 음성 제작 능력을 제공할 수 있게 되었다. ThinkSound는 문턱이 높았던 전문 음향 기술을 일반 개발자들도 쉽게 활용할 수 있도록 대중화 시킨 혁신적인 기술이라 평가 받고 있다.




