
알리바바가 야심차게 차세대 인공지능 모델 아키텍처를 공개하며 AI 업계에 또 한 번 파장을 일으키고 있다. 9월 12일 새벽, 알리바바 통이실험실이 정식 발표한 ‘Qwen3-Next’ 아키텍처는 기존 모델 대비 훈련 비용을 90% 이상 절감하면서도 성능은 오히려 향상시키는 혁신적 기술력을 선보였다.

800억 파라미터에서 30억만 활성화하는 초효율 설계
이번에 공개된 Qwen3-Next-80B-A3B-Base 모델은 총 800억 개의 파라미터를 보유하고 있지만, 실제로는 단 30억 개의 파라미터만 활성화하는 획기적인 구조를 채택했다. 이는 기존 Qwen3-32B 모델 대비 GPU 컴퓨팅 리소스를 단 9.3%만 사용하면서도, 32,000 토큰을 초과하는 컨텍스트에서 추론 처리량을 10배 이상 향상시키는 성과를 달성했다.
알리바바는 이 기반 모델을 바탕으로 두 가지 특화 버전을 함께 오픈소스로 공개했다. 바로 명령어 처리에 특화된 ‘Qwen3-Next-80B-A3B-Instruct’ 모델과 사고 과정을 시뮬레이션하는 ‘Qwen3-Next-80B-A3B-Thinking’ 모델이다. 두 모델 모두 네이티브 262,144개 토큰 컨텍스트 길이를 지원하며, 최대 1,010,000개 토큰까지 확장 가능하다.
특히 명령어 모델인 Instruct 버전은 일반적인 지시사항 처리에 최적화되어 있으며, 블록을 생성하지 않는 순수 명령 실행 모드로 작동한다. 반면 Thinking 모델은 사고 과정을 시뮬레이션하는 데 특화되어 있어, 기본 채팅 템플릿에 자동으로 태그가 포함되어 모델이 사고 과정을 거치도록 설계되었다.
구글 제미나이 2.5 플래시를 뛰어넘는 성능
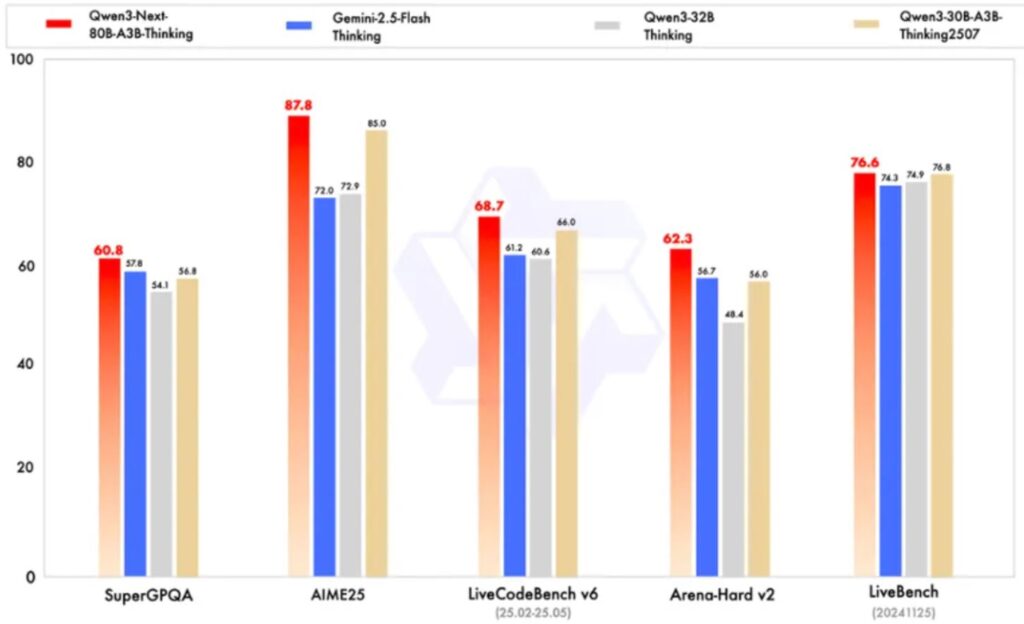
성능 측면에서 Qwen3-Next는 놀라운 결과를 보여주고 있다. 명령어 모델의 경우 파라미터 규모가 훨씬 큰 Qwen3-235B-A22B-Instruct-2507 모델과 거의 동등한 성능을 달성했다. 더욱 주목할 만한 점은 사고 모델(Thinking)이 구글의 비공개 모델인 Gemini-2.5-Flash-Thinking을 능가하는 성능을 보였다는 것이다.
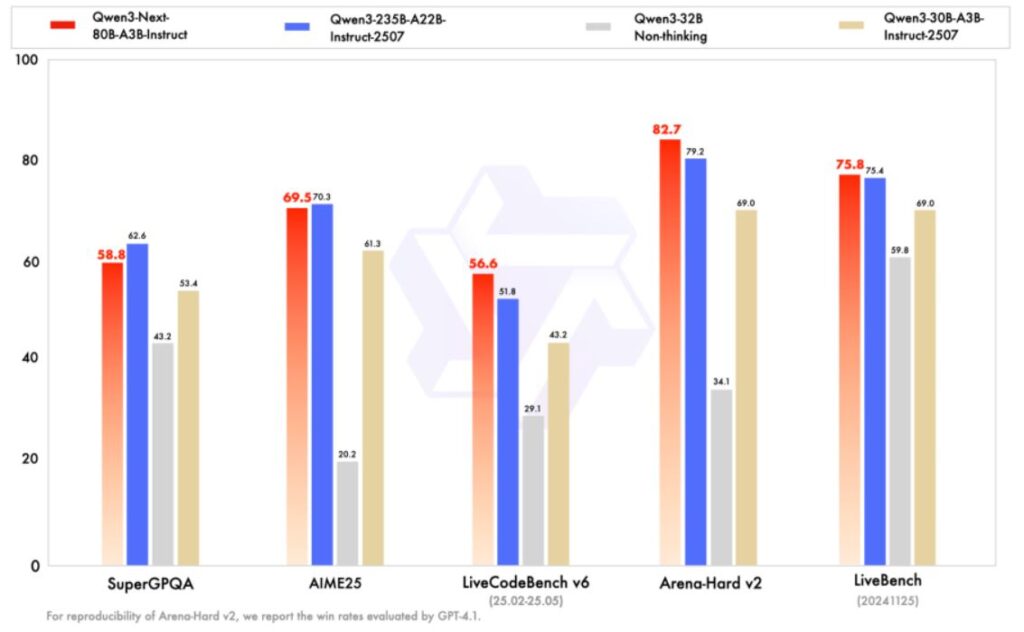
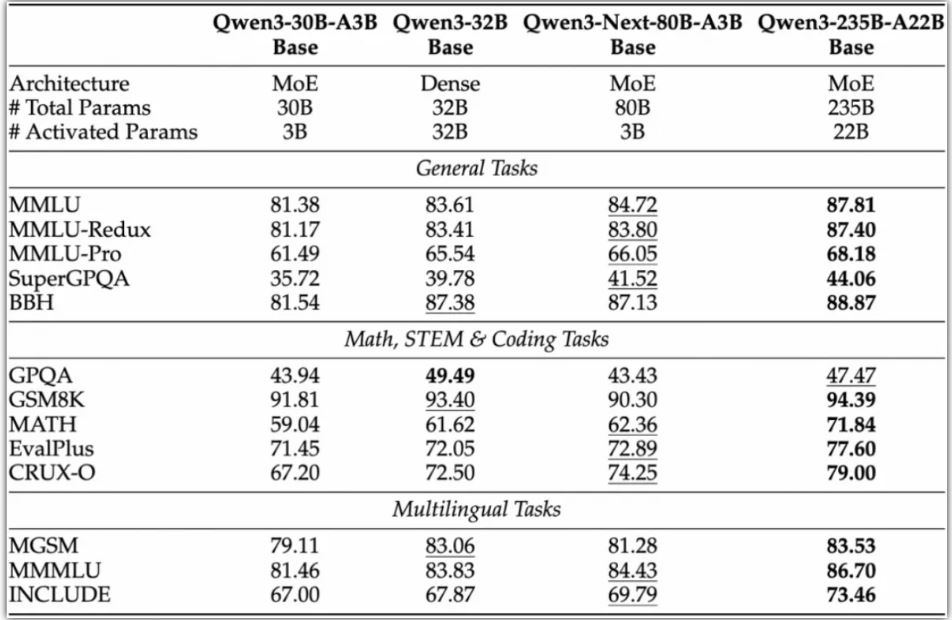
기반 모델인 Qwen3-Next-80B-A3B-Base는 Non-Embedding 활성화 파라미터의 1/10만을 사용하면서도 대부분의 벤치마크 테스트에서 Qwen3-32B-Base와 유사한 성능을 발휘했다. 총 훈련 비용은 Qwen3-32B-Base의 10% 미만에 불과하면서도, 32,000개 이상의 컨텍스트에서는 10배 이상의 추론 처리량을 실현했다.
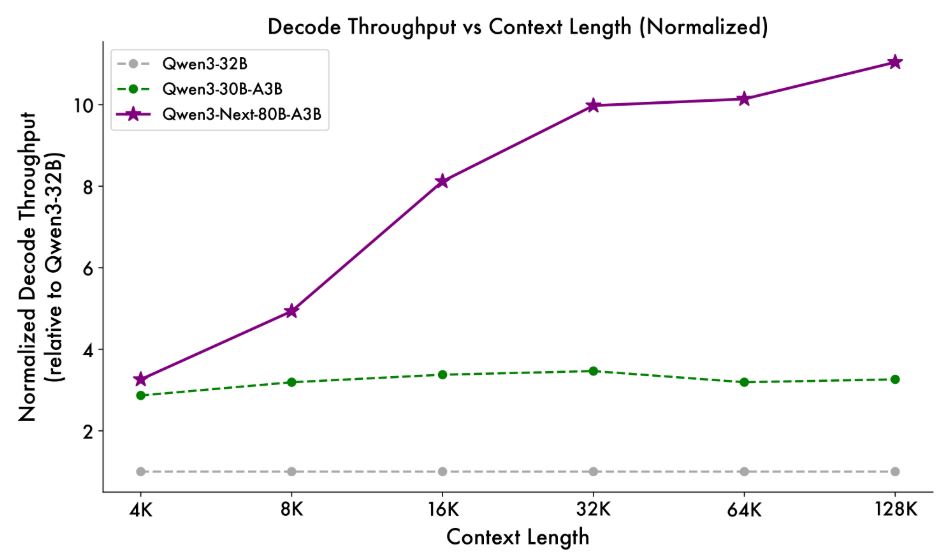
구체적인 성능 지표를 살펴보면, 새로운 혼합 모델 아키텍처 덕분에 Qwen3-Next-80B-A3B는 프리필(prefill) 단계에서 4,000 토큰 컨텍스트 길이 조건에서 기존 모델 대비 7배 가까운 처리량을 보였다. 컨텍스트 길이가 32,000개를 초과할 때는 처리량 향상폭이 10배 이상으로 확대되었다.
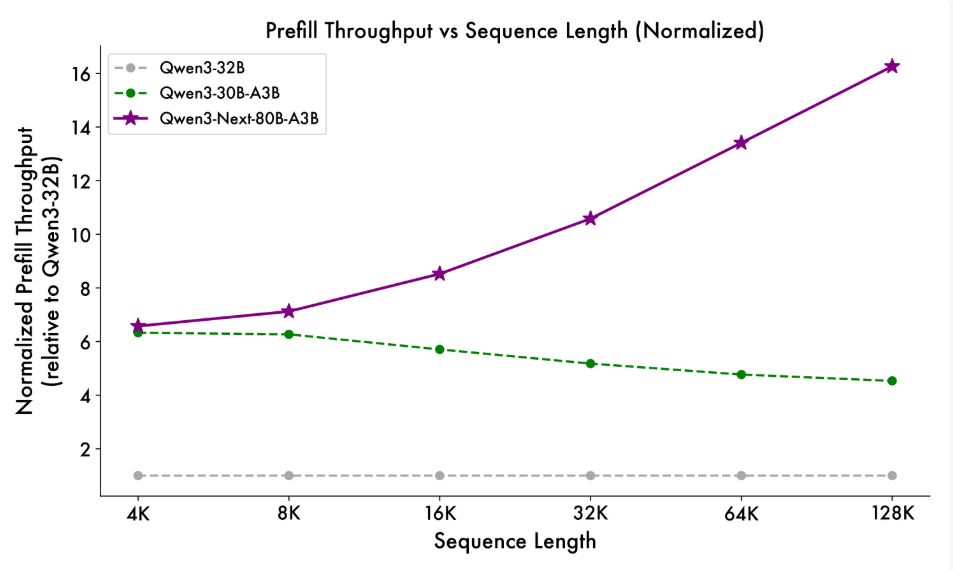
디코딩(decode) 단계에서도 마찬가지로 뛰어난 성능을 보여, 4,000개 컨텍스트에서 거의 4배의 처리량 향상을 달성했으며, 32,000개 이상의 장기 컨텍스트 시나리오에서는 10배 이상의 처리량 우위를 유지했다.
4가지 핵심 기술 혁신으로 달성한 비약적 성능
Qwen3-Next가 이 같은 혁신적 성능을 달성할 수 있었던 배경에는 4가지 핵심 기술이 있다.
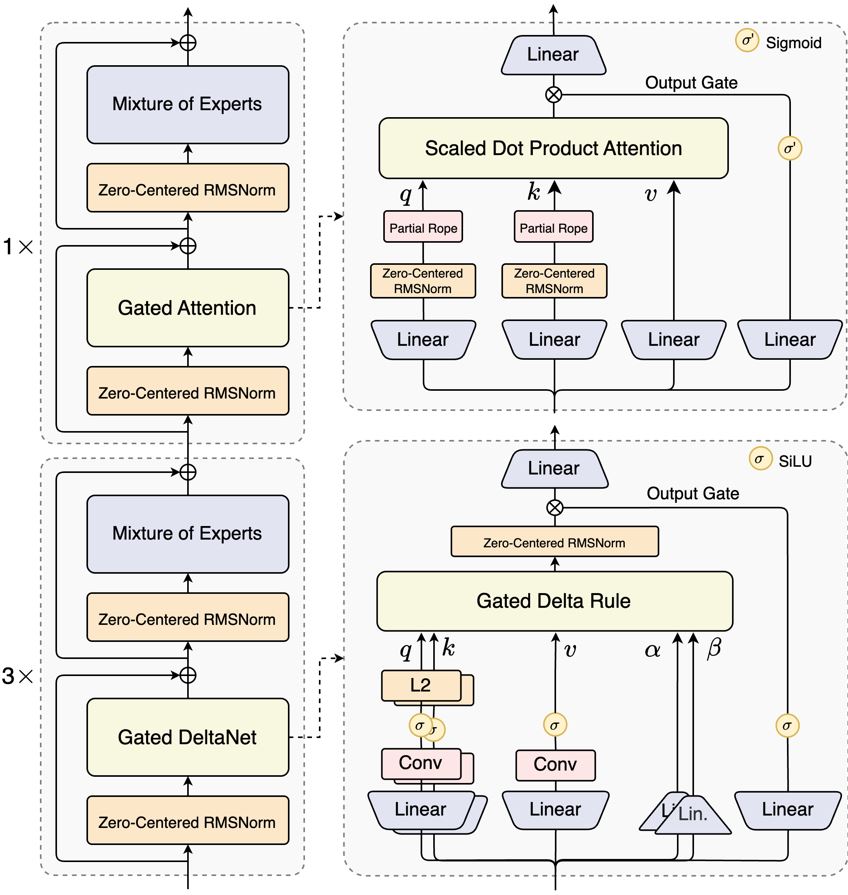
먼저 혼합 어텐션 메커니즘(Hybrid Attention Mechanism)이다. 기존의 표준 어텐션을 게이티드 델타넷(Gated DeltaNet, 선형 어텐션)과 게이티드 어텐션(Gated Attention, 게이트 제어 어텐션)의 조합으로 대체하여 초장기 컨텍스트 길이에서도 효과적인 컨텍스트 모델링을 구현했다.
연구진의 실험 결과, 게이티드 델타넷은 일반적으로 사용되는 슬라이딩 윈도우 어텐션(Sliding Window Attention)이나 Mamba2보다 더 강력한 컨텍스트 학습 능력을 보였다. 특히 3:1의 혼합 비율, 즉 75%의 레이어에서 게이티드 델타넷을 사용하고 25%의 레이어에서 표준 어텐션을 유지하는 구조가 단일 아키텍처를 일관되게 능가하며 성능과 효율성의 이중 최적화를 달성했다.
두 번째는 고희소성 혼합 전문가(High Sparsity MoE) 구조다. MoE 레이어에서 극도로 낮은 활성화 비율을 구현하여 각 토큰의 FLOP를 대폭 감소시키면서도 모델 용량은 유지했다. 이전 Qwen3 시리즈의 MoE 전문가 활성화 비율이 약 1:16이었던 반면, Qwen3-Next는 1:50의 활성화 비율을 달성했다.
세 번째는 안정성 최적화다. 제로 중심화(Zero-centering)와 가중치 감소 레이어노름(Weight Decay LayerNorm) 등의 기술을 포함하여 견고한 사전 훈련과 후속 훈련을 위한 안정성을 강화했다. 특히 어텐션 출력 게이트 메커니즘이 어텐션 풀링과 극대 활성화 현상을 제거하여 모델 각 부분의 수치적 안정성을 보장한다.
네 번째는 다중 토큰 예측(Multi-Token Prediction, MTP) 메커니즘이다. 이 기술은 사전 훈련 모델의 성능을 향상시키고 추론을 가속화한다. Qwen3-Next는 특히 MTP의 다단계 추론 성능을 최적화했으며, 훈련-추론 일관성을 갖춘 다단계 훈련을 통해 실용적 시나리오에서 Speculative Decoding 수락률을 더욱 향상시켰다.
개발자 커뮤니티의 뜨거운 반응
Qwen3-Next의 공개와 함께 개발자 커뮤니티에서는 뜨거운 반응이 이어지고 있다. 특히 개발자들은 새롭게 추가된 다중 토큰 예측(MTP) 메커니즘을 가장 인상적인 부분으로 꼽고 있다. X(구 트위터)의 Qwen 계정 댓글란에는 이 기능에 대한 찬사가 줄을 이었다.
현재 새로운 모델은 魔搭社區(ModelScope)와 허깅페이스(HuggingFace)에서 오픈소스로 공개되어 있으며, 개발자들은 Qwen Chat을 통해 무료로 체험하거나 알리클라우드 百炼(Bailian), NVIDIA API 카탈로그를 통해 Qwen3-Next를 경험할 수 있다.
장기 컨텍스트 처리에서 탁월한 성능
Qwen3-Next-80B-A3B-Instruct는 RULER 벤치마크에서 모든 길이 구간에 걸쳐 동일한 레이어 수와 더 많은 어텐션 레이어를 가진 Qwen3-30B-A3B-Instruct-2507을 명확히 앞섰다. 심지어 256,000 토큰 범위 내에서는 레이어 수가 더 많은 Qwen3-235B-A22B-Instruct-2507까지 능가하는 성능을 보였다.
사고 모델의 경우 사전 훈련 비용이 더 높은 Qwen3-30B-A3B-Thinking-2507, Qwen3-32B-thinking 모델들을 능가했으며, 구글의 비공개 모델 Gemini-2.5-Flash-Thinking을 전면적으로 뛰어넘었다. 일부 지표에서는 알리바바의 최신 플래그십 모델 Qwen3-235B-A22B-Thinking-2507에 근접하는 성능을 보였다.
미래를 위한 확장성 설계
연구진은 블로그를 통해 Qwen3-Next가 대형 언어 모델이 컨텍스트 길이와 총 파라미터 두 측면에서 지속적으로 확장되는 미래 트렌드에 대응하여 설계되었다고 밝혔다. 이 모델은 Qwen3 36T 사전 훈련 코퍼스의 균등 샘플링 부분집합인 15T 토큰을 사용했으며, 훈련에 소모된 GPU 시간은 Qwen3-30A-3B의 80% 미만이었다.
특히 주목할 점은 훈련 효율성이다. Qwen3-32B와 비교할 때 단 9.3%의 GPU 컴퓨팅 리소스만으로도 더 우수한 모델 성능을 달성했다. 이는 AI 모델 개발에서 비용 효율성이 얼마나 중요한지를 보여주는 대표적 사례라 할 수 있다.
연구진은 향후 이 아키텍처를 지속적으로 최적화하고 Qwen3.5를 개발할 계획이라고 밝혔다. 동시에 최근 알리바바 통이는 수만억 파라미터의 Qwen3-Max-Preview, 텍스트-이미지 생성 및 편집 모델 Qwen-Image-edit, 음성 인식 모델 Qwen3-ASR-Flash 등 다양한 분야의 모델들을 연이어 선보이고 있다. 이러한 다영역 모델의 지속적인 출시와 오픈소스화를 통해 알리바바 통이는 오픈소스 커뮤니티에서의 기술적 영향력을 점진적으로 강화해 나가고 있다.
Qwen3-Next의 혁신은 대규모 파라미터 용량, 낮은 활성화 오버헤드, 장기 컨텍스트 처리, 병렬 추론 가속을 동시에 실현했다는 점에 있다. 어텐션 메커니즘, MoE 설계 등 여러 아키텍처 혁신을 결합하여 단 30억 개의 활성화 파라미터만으로도 규모가 훨씬 큰 모델의 성능에 맞먹는 결과를 달성함으로써, 성능과 효율성 사이의 더 나은 균형점을 찾아냈다. 이는 모델 훈련 및 추론 비용 절감을 위한 효과적인 경로를 제시하고 있어, 향후 AI 산업 전반에 미칠 파급효과가 클 것으로 예상된다.
[Qwen 채팅 주소]
https://chat.qwen.ai
[Hugging Face]
https:// huggingface.co/collections/Qw en/qwen3-next-68c25fd6838e585db8eeea9d
[Alibaba Cloud Bailian]
https://bailian.console.aliyun.com/?tab=model#/model-market/detail/qwen3?modelGroup=qwen3
[관련 기사]
알리바바 Qwen3 임베딩·리랭킹 모델 공개, MTEB 벤치마크 1위 달성




