

실제 로봇으로 신발끈 끼우기 83.3% 성공률 달성
바이트댄스의 Embodied AI 팀인 ‘Seed‘가 12월 2일 새로운 강화학습 모델 GR-RL을 발표하며 로봇 기술의 새로운 이정표를 제시했다. 이번 연구에서 가장 주목 받는 성과는 실제 로봇이 “신발 전체에 연속으로 신발끈 끼우기” 작업을 완수한 것으로, 성공률을 기존 45.7%에서 83.3%로 끌어올리며 실패율을 약 70% 감소시켰다.
이번 연구에 사용된 로봇은 새로 공개된 ByteMini-v2로, 기존의 모방학습(Imitation Learning) 방식과 달리 실제 환경에서의 강화학습(Real-world Reinforcement Learning)을 통해 훈련되었다. 이는 로봇이 단순히 인간의 동작을 따라 하는 것이 아니라, 시행착오를 통해 스스로 최적의 전략을 찾아나가는 방식이다.
바이트댄스 Seed 팀은 올해 7월 범용 로봇 모델 GR-3과 양팔 이동 로봇 ByteMini를 발표한 바 있다. 당시에도 일반화 능력, 새로운 환경 적응력, 유연한 물체 조작 능력을 선보여 업계의 주목을 받았다. 이번 연구는 장시간에 걸친 정밀하고 정교한 조작 작업에서 한 단계 더 발전된 모습을 보여주고 있다.

신발끈 끼우기가 가진 기술적 도전과제
바이트댄스 Seed 팀이 신발끈 끼우기를 검증 작업으로 선정한 이유는 이 작업이 실제 환경에서 로봇이 직면하는 세 가지 핵심 난제를 모두 포함하고 있기 때문이다.
첫째는 유연한 물체의 불확실성이다. 신발끈은 당겨지거나 마찰을 받을 때마다 실시간으로 상태가 변하며, 로봇은 이러한 변화에 즉각적으로 대응해야 한다.
둘째는 밀리미터 단위의 정밀도가 요구되는 구멍 뚫기 작업이다. 신발 구멍의 지름이 작기 때문에 잡는 각도에 대한 요구사항이 매우 까다롭다.
셋째는 여러 단계로 이루어진 연속 실행의 안정성이다. 전체 과정이 수 분간 지속될 수 있으며, 매번 발생하는 미끄러짐, 편향, 자세 변화가 모두 후속 동작에 영향을 미칠 수 있다.
연구팀은 기존에 상당한 일반화 능력을 보여준 범용 모델 GR-3조차 이 작업에서는 불안정한 성능을 보인다는 점을 발견했다. 이를 모방학습 방식의 구조적 한계로 분석했다.
문제점은 크게 두 가지로 요약된다.
하나는 인간 시연 데이터에 포함된 “차선의 구간들”이다. 인간의 시연에는 속도를 늦추거나 망설이고, 시도하다가 되돌리는 등의 구간이 포함되어 있어, 모델이 학습 과정에서 이를 함께 흡수하게 된다. 그 결과 “동작이 보수적”이거나 “실행 중 정지”하는 행동이 나타난다.
다른 하나는 훈련과 추론 사이의 “실행 불일치”다. 훈련 단계에서는 동작 예측을 학습하지만, 실제 배치 시 실행되는 동작은 추론 과정의 평활화, 궤적 형성 등의 처리를 거친다. 이러한 훈련과 실행 사이의 편차는 밀리미터 단위 작업에서 크게 증폭된다.
GR-RL의 혁신적 접근: “나쁜 동작” 필터링부터 시작
GR-RL은 단순히 데이터량을 늘리거나 훈련 시간을 연장하는 방식이 아니라, 구조적으로 추가적인 판별기 네트워크(Critic Transformer)를 도입했다. 이 네트워크는 각 동작 구간의 가치를 판단하여 동작 시퀀스의 모든 순간마다 점수를 매긴다.
연구팀은 오프라인 데이터에서 “시연 재시작”의 핵심 프레임을 표시하고, 그 이전 구간을 부정적 샘플로 간주하여 실패 데이터 소스를 보완했다. 이는 모델이 지도학습 이전에 먼저 어떤 행동이 후속 실행에서 실패로 이어질지 구별할 수 있게 하는 것이 목적이다.
이를 바탕으로 시간차 방법을 사용해 평가 네트워크를 훈련시키고, 동작의 결과를 보상 신호로 활용해 품질이 낮은 궤적 구간을 필터링했다. 상대적으로 안정적인 시연 데이터만 보존하여 기본 전략으로 삼았다.
신발끈 끼우기는 공간적 관계와 양손 협응 동작을 포함하므로, 연구팀은 이미지, 로봇 상태, 동작 궤적에 대해 미러링 증강을 적용했다. 이를 통해 모델이 양팔 협업에서 대칭성 이해를 획득하고, 단일 시연 경로에 대한 의존성을 줄일 수 있었다.
GR-RL 훈련의 두 번째 단계는 실제 로봇에서 진행된다. 연구팀은 가이드 강화학습 방법을 채택하여, 관절 차원에서 무작위로 교란하는 대신 모델이 생성하는 동작의 잠재공간 노이즈를 조정했다. 이를 통해 실제 탐색에서 점진적으로 더 높은 보상의 전략에 접근할 수 있게 했다.
“이전 전략을 잊어버리거나” 단기적 편향을 방지하기 위해 “듀얼 버퍼풀” 전략을 도입했다. 역사적 궤적과 최신 궤적을 분리하여 저장하고, 훈련 시 고정된 비율로 추출하여 탐색과 안정성을 병행했다.
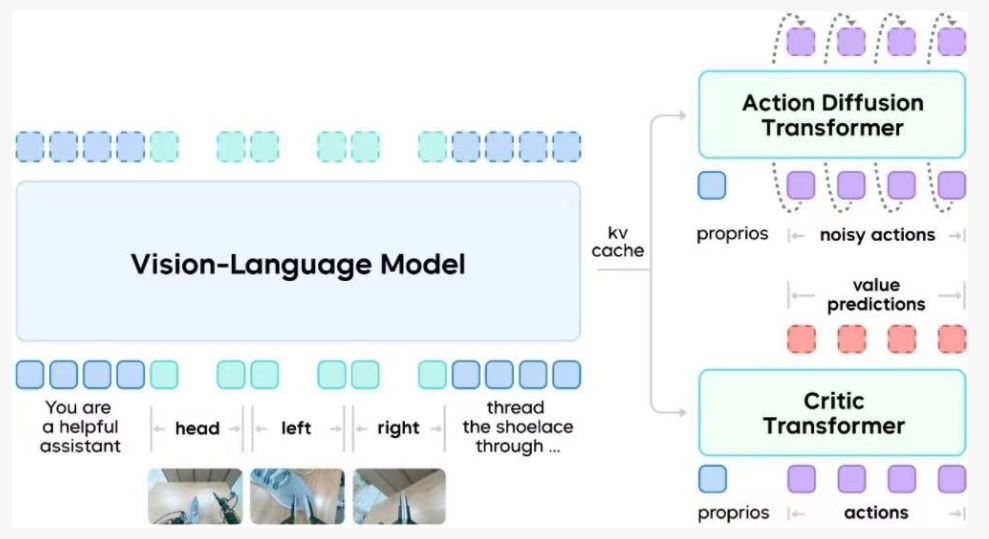
ByteMini-v2로 실제 검증, 단계별 성능 향상 확인
GR-RL의 검증은 양팔 바퀴형 로봇 ByteMini-v2에서 완성되었다. 초기 모델과 비교해 다자유도 구조를 유지하면서도, 구형 손목 관절을 통해 더욱 유연한 국소 동작 공간을 확보했다. 이는 좁은 영역에서 회전과 관통 작업을 완성하기에 적합하다.
실험에서는 희소 보상 전략을 사용했다. 즉, 작업이 완전히 완료되었을 때만 점수를 주고, 나머지 상황은 모두 0점으로 설정했다. 이러한 설정은 모델이 국소적 중간 상태에 과도하게 의존하는 것을 방지하고, 전체적 전략에 대한 제약을 강화했다.
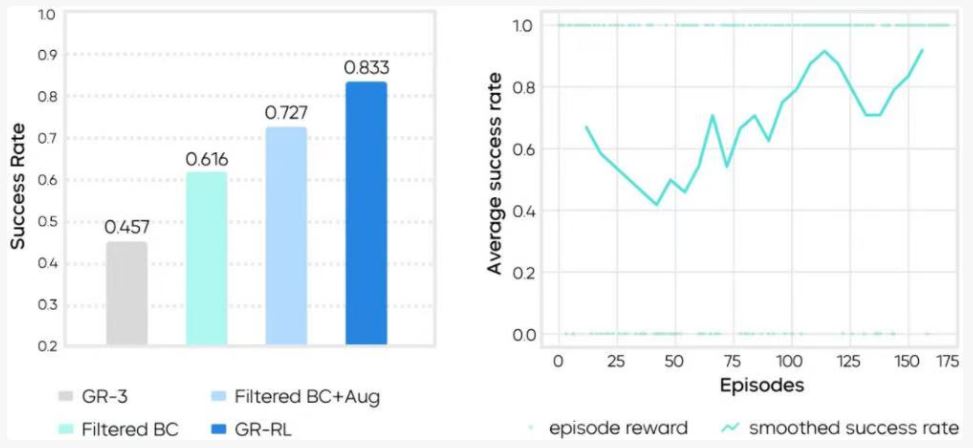
실험 결과, 기준 모델 GR-3의 성공률은 45.7%였다. 오프라인 데이터 필터링 후에는 61.6%로 향상되었고, 미러링 증강을 추가한 후에는 72.7%에 달했다. 이를 기반으로 약 150개의 실제 기계 탐색을 진행한 후, 최종 성공률은 83.3%에 도달했다. 이러한 결과는 명확한 “단계별” 변화를 보여주며, 훈련 과정의 각 단계별 역할과 일치한다.
여러 차례 실험에서 연구팀은 작업 실행 과정의 행동 변화도 관찰했다. 신발끈이 관통 과정에서 떨어졌을 때 모델은 다시 잡거나 각도를 조정했고, 초기 배치에서 방해물이 있을 때는 상태를 바꾼 후 작업을 계속 진행했다. 이러한 행동들은 별도로 코딩 된 것이 아니라 강화 단계에서 점진적으로 형성된 전략적 표현이다.
구글, 메타와 비교되는 중국 로봇 기술의 약진
이번 바이트댄스의 성과는 구글의 RT 시리즈나 메타의 로봇 연구와 비교해볼 때 실제 환경에서의 정밀 조작 능력에서 한 단계 앞서는 모습을 보여준다. 특히 구글의 RT-X나 RT-2가 다양한 환경에서의 일반화에 초점을 맞춘 반면, 바이트댄스는 특정 고난도 작업에서의 성공률 극대화에 집중했다는 점에서 차별화된다.
또한 OpenAI의 로봇 연구나 Boston Dynamics의 Atlas와 비교할 때, 바이트댄스 ByteMini-v2는 휴머노이드 로봇이 아닌 바퀴형 양팔 로봇이라는 점에서 실용성을 우선시한 설계 철학을 보여준다. 이는 중국 IT 기업들이 기술적 과시보다는 상용화 가능한 솔루션 개발에 더 관심이 있음을 시사한다.
테슬라의 옵티머스(Optimus) 로봇이 아직 기본적인 물체 조작 수준에 머물러 있는 것과 비교하면, 바이트댄스의 로봇이 보여준 정밀 조작 능력은 상당히 앞서 있다고 평가할 수 있다. 특히 신발끈이라는 유연한 재질의 연속적 조작은 기존 로봇들이 시연하지 못한 새로운 영역으로, 언뜻 사소해 보이지만 실제로는 의료용 로봇의 정밀 수술, 제조업의 미세 조립, 고령자 돌봄 서비스 등 다양한 분야로 확장 가능한 핵심 기술이다.
더 중요한 것은 바이트댄스의 이번 연구가 보여주는 접근 방식의 변화다. 기존의 모방학습에서 벗어나 실제 환경에서의 강화학습으로 전환한 것은 로봇이 정해진 시나리오를 벗어난 상황에서도 대응할 수 있는 진정한 ‘지능’을 갖추어가고 있음을 의미한다. 이는 앞으로 가정용 로봇 시장이 급격히 성장할 가능성을 시사하며, 한국 기업들도 이에 맞는 장기적 R&D 전략을 수립해야 할 시점이다.
(관련 기사) 중국 첫 밀리미터 급 휴머노이드 로봇, DOBOT Atom Ⅱ 공개




