
바이트댄스와 홍콩과기대 광저우캠퍼스가 공동 개발한 혁신적인 오픈소스 시각 생성 프레임워크 ‘ComfyMind’가 공개되어 AI 창작 분야에 새로운 변화를 예고하고 있다. 이 프레임워크는 단일 시스템으로 텍스트-이미지, 이미지-비디오 등 모든 주류 시각 생성 작업을 통합 처리할 수 있는 능력을 갖춘 것으로 평가 받고 있다.

ComfyMind의 핵심 기능과 성능
ComfyMind는 사용자가 한 문장으로 아이디어를 설명하기만 하면 자동으로 작업 흐름을 구축하고, 도구를 선택하며, 반복적인 수정을 통해 최종적으로 고품질의 시각 작품을 제공하는 ‘AI 창작 마스터’ 역할을 수행한다. 다양한 업계 벤치마크 테스트에서 ComfyMind는 기존 오픈소스 방법들을 전면적으로 능가하며, 클로즈드 소스인 GPT-4o-Image와 견줄 만한 수준의 성능을 달성했다.
실제 활용 사례를 살펴보면, ComfyMind는 광학 지식을 결합하여 유리 프리즘의 빛 산란 이미지를 생성하거나, 케이크 이미지에서 특정 부분을 자르는 작업, 로고를 컵에 자연스럽게 삽입하는 작업, 심지어 8초 길이의 해변 모닥불 영상 생성까지 다양한 작업을 손쉽게 처리할 수 있다.



기존 한계점을 극복한 혁신적 접근법
현재까지 시각 생성 모델들이 급속도로 발전했음에도 불구하고, ‘하나의 시스템으로 모든 작업 처리’가 가능한 오픈소스 프레임워크는 여전히 취약하여 실제 제작 요구사항을 충족하기 어려웠다. 반면 클로즈드 소스인 GPT-Image-1(GPT-4o-Image)은 뛰어난 효과를 보이지만 커뮤니티에서 자유롭게 확장하거나 최적화할 수 없다는 한계가 있었다.
ComfyUI의 노드 방식 설계는 ‘시각화, 모듈화’의 기초를 다졌고, 이론적으로는 어떤 작업이든 노드 조합을 통해 완성할 수 있다. 하지만 작업 흐름이 다중 모달리티, 다중 단계에 걸칠 때 수동 구축은 시간과 노력이 많이 들 뿐만 아니라 전문 지식에 대한 요구 사항이 매우 높아 창작의 진입 장벽이 되었다.
ComfyAgent 등 LLM 기반 솔루션들이 이미 자동 작업 흐름 생성을 시도했지만, 이들은 평면적 JSON 디코딩에 의존하여 모듈 계층을 표현하기 어렵고 실행단 피드백이 부족해 노드 누락과 의미적 이탈 문제를 야기했다.
인간 예술가의 작업 방식을 모방한 설계
인간 예술가들이 복잡한 프로세스를 구축할 때 먼저 작업을 분해한 후 부분적으로 시행착오를 거쳐 부분적으로 수정하는 전략에서 영감을 얻어, 연구팀은 ComfyMind를 제안했다. 이 시스템은 ‘원자 작업 흐름’을 최소 단위로 하고, 자연어 설명 인터페이스와 결합된 트리 형태의 계획 및 부분 피드백 실행을 통해 시각 콘텐츠 창작을 계층적 의사결정 문제로 전환한다. 이를 통해 유연성을 유지하면서도 안정성과 확장성을 크게 향상시켰다.
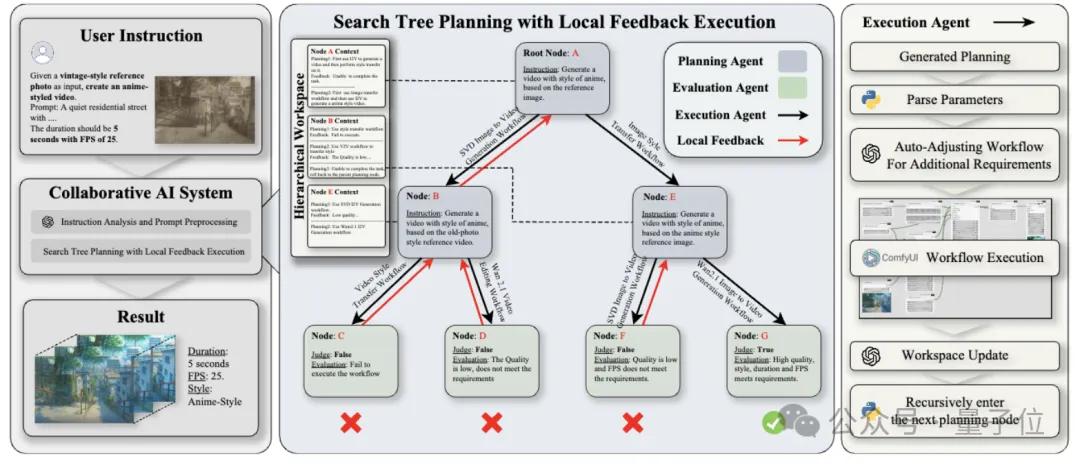
시스템 아키텍처: ‘ComfyUI × 다중 에이전트 협업’
ComfyMind는 ComfyUI를 단순히 하위 실행 엔진으로만 취급하며, 모든 고수준 의사결정은 계획-실행-평가라는 세 가지 에이전트의 협력으로 완성된다. 계획 에이전트는 상향식으로 작업을 분해하고, 실행 에이전트는 각 단계를 JSON 작업 흐름으로 매핑하여 ComfyUI와 결합해 구체적인 생성을 수행한다. 평가 에이전트는 생성 프로세스가 끝날 때 VLM을 사용해 생성 품질과 지시사항 일치성을 판단하고, 진단 정보를 상위 계층으로 반환한다.
의미적 작업 흐름 인터페이스
연구팀이 제안한 의미적 작업 흐름 인터페이스는 커뮤니티에서 검증된 T2I, I2V, Mask 생성 등의 템플릿을 ‘원자 작업 흐름’으로 캡슐화하고, 자연어로 그 기능과 필수/선택 매개변수를 표시한다. 따라서 계획 에이전트는 순수한 의미 공간에서 고차 함수를 호출하듯 모듈을 조합할 수 있으며, 오류가 발생하기 쉬운 JSON 구문을 다룰 필요가 없어 ‘노드 누락’, ‘연결 오류’ 등의 구조적 장애를 완전히 제거한다.
성능 평가와 벤치마크 결과
ComfyMind의 성능을 검증하기 위해 세 가지 주요 벤치마크에서 종합적인 평가가 실시되었다.
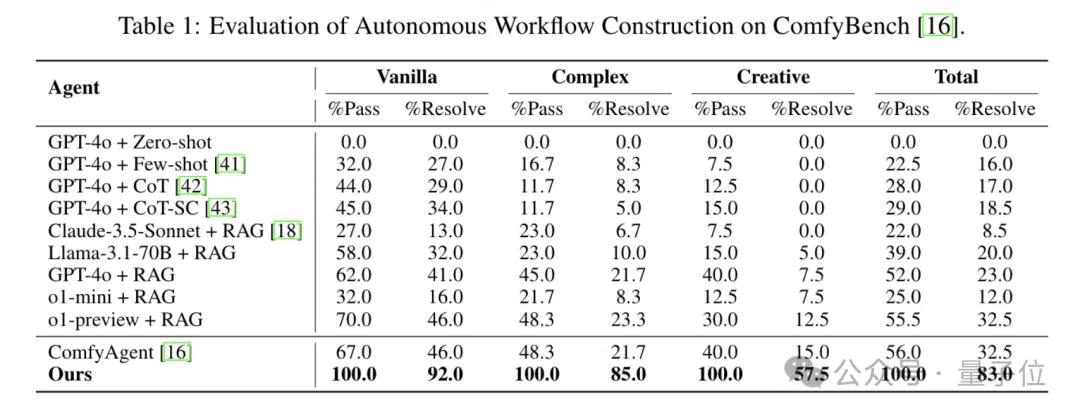
ComfyBench 자동 작업 흐름 구성
ComfyMind는 ComfyBench의 모든 난이도 작업에서 100% 통과율을 달성하여 JSON 수준의 실패를 완전히 제거했다. 동시에 Vanilla, Complex, Creative 난이도에서 문제 해결률을 ComfyAgent 대비 각각 100%, 292%, 283% 향상시켜 다중 에이전트-ComfyUI 체계가 범용 생성 및 편집 작업에서 뛰어난 일반화 능력과 출력 품질을 보유하고 있음을 입증했다.
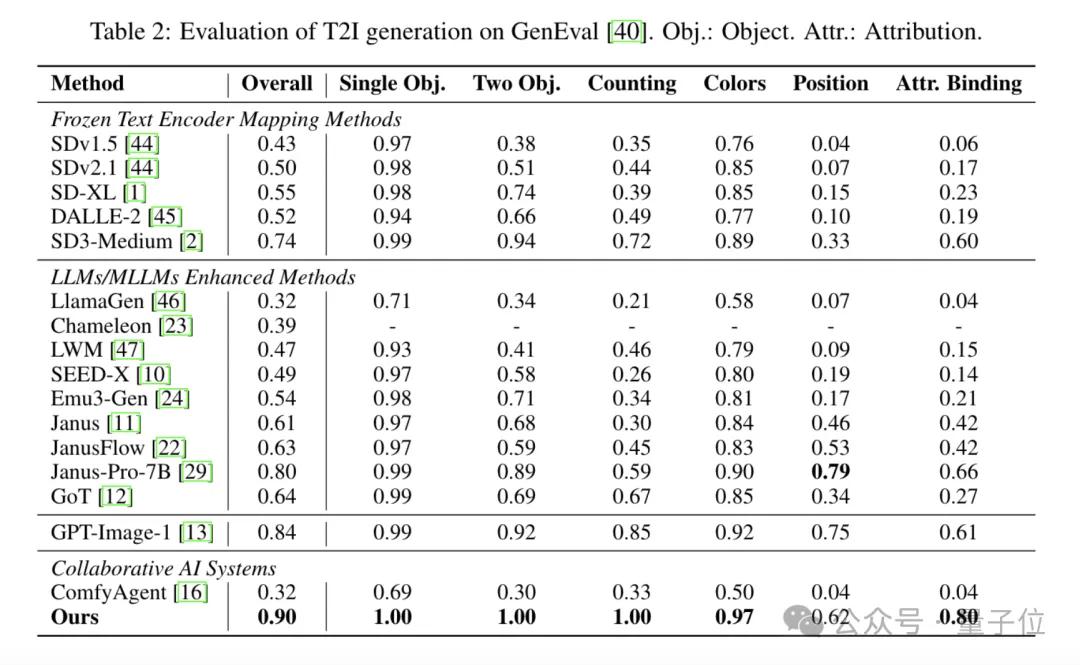
GenEval 텍스트-이미지 생성
GenEval에서 ComfyMind는 0.90의 총점을 획득하여 오픈소스 기준인 SD3과 Janus-Pro-7B를 각각 0.16, 0.10 앞서며, 6개 주요 차원 중 5개 항목과 전체 성과에서 GPT-Image-1을 능가했다. 정성적 비교를 통해서도 다양한 제약 조건 하에서 본 시스템이 지시사항을 충족하면서 동시에 시각적으로 일관된 고품질 이미지를 생성함을 확인할 수 있었다.

Reason-Edit 이미지 편집
Reason-Edit 벤치마크에서 ComfyMind는 0.906의 GPT-score로 이전 오픈소스 SOTA인 SmartEdit보다 +0.334 향상된 성과를 보였으며, GPT-Image-1(0.929)에 근접한 수준을 달성했다. 정성적 비교에서도 ComfyMind가 복잡한 편집 지시사항을 정확히 완수하면서 동시에 비편집 영역의 세부사항과 스타일 일관성을 유지하는 것으로 나타났다.

향후 전망과 의의
ComfyMind 프레임워크는 이전의 오픈소스 방법들을 성능상 압도하며 GPT-Image-1과 견줄 만한 결과를 달성했다는 점에서 큰 의미를 갖는다. 특히 관련 논문, 온라인 데모, 코드, 프로젝트 홈페이지 등이 모두 공개되어 연구자들과 개발자들이 자유롭게 활용하고 확장할 수 있다는 점이 주목할 만하다.
이 프레임워크는 시각 콘텐츠 창작을 모듈화되고 의미적으로 구조화된 계획 프로세스로 개념화하고, 트리 기반 계획과 부분 피드백 실행을 결합함으로써 기존의 한계를 극복했다. 이는 AI 기반 창작 도구의 새로운 패러다임을 제시하며, 전문가가 아닌 일반 사용자도 복잡한 시각 생성 작업을 쉽게 수행할 수 있는 환경을 조성한다.
향후 ComfyMind는 더욱 다양한 시각 생성 작업으로 확장될 것으로 예상되며, 오픈소스 특성상 커뮤니티의 기여를 통해 지속적인 발전을 이룰 것으로 전망된다. 이는 AI 시각 생성 분야에서 중국 기술의 선도적 위치를 다시 한번 확인시켜주는 성과로 평가받고 있다.
[논문 링크]
https://arxiv.org/abs/2505.17908
[프로젝트 홈페이지]
https://litaoguo.github.io/ComfyMind.github.io/
[온라인 데모 링크]
https://envision-research.hkust-gz.edu.cn/ComfyMind/




