
상하이AI연구소가 여러 연구기관과 협력하여 획기적인 보편적 구현형 지능 대뇌 프레임워크인 ‘Visual Embodied Brain(VeBrain)’을 발표했다. 이 혁신적인 시스템은 시각 인지, 공간 추론, 로봇 제어 능력을 동시에 통합하여 다중모달 대형 모델(MLLM)이 물리적 실체를 직접 조작할 수 있게 한다.


VeBrain의 핵심 기술적 혁신
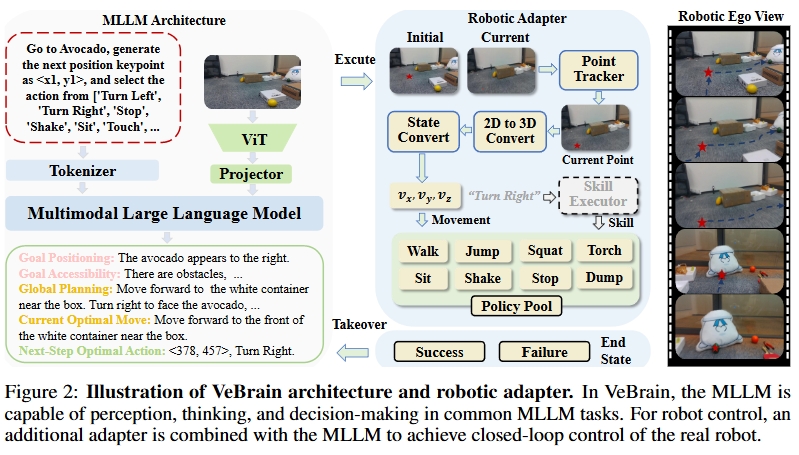
VeBrain은 기존의 MLLM과 시각-언어-동작(VLA) 모델과 비교해 여러 가지 혁신적인 특징을 보여준다. 먼저 세 가지 유형의 작업을 통합하는 언어 모델링 패러다임을 구축했다. 로봇 제어를 MLLM의 일반적인 2D 공간 텍스트 작업으로 전환하여 키포인트 검출과 구현 기술 식별 등의 작업을 통해 인지, 추론, 제어 세 가지 핵심 능력의 모델링 경로를 연결했다.
특히 주목할 만한 것은 ‘로봇 어댑터’ 개념의 도입이다. 이 시스템은 키포인트 추적, 동작 제어, 기술 실행, 동적 인수인계 모듈로 구성되어 텍스트 결정에서 실제 동작까지의 정밀한 매핑을 실현한다. 이를 통해 MLLM과 로봇 간의 폐루프 통신이 가능해져 동적 환경에서의 안정성과 견고성이 크게 향상되었다.
VeBrain-600K 데이터셋의 구축
VeBrain 팀은 모델의 통합 훈련을 지원하기 위해 VeBrain-600k라는 고품질 다능력 데이터셋을 구축했다. 이 데이터셋은 총 60만 개의 지시 데이터를 포함하며, 다중모달 이해, 시각-공간 추론, 로봇 조작 세 가지 작업 영역을 포괄한다.
구체적으로 살펴보면, 20만 개의 다중모달 이해 데이터는 이미지, 비디오, 텍스트를 통합하여 ShareGPT4V, MMInstruct 등에서 수집했다. 31.2만 개의 공간 추론 데이터는 ScanNet 포인트 클라우드 데이터를 결합하여 계수, 거리, 크기 등의 공간 이해 작업을 생성했다. 8.8만 개의 로봇 제어 데이터는 인공 수집 및 주석이 달린 실제 로봇 조작 데이터로, 사족 로봇과 로봇 팔 두 가지 플랫폼을 다룬다.
데이터 품질 향상을 위해 대량의 작업에 사고의 연쇄(Chain-of-Thought, CoT) 구조를 도입했다. GPT-4o와 Gemini가 자동으로 추론 과정을 생성하고 전문가가 검토하여 데이터 품질과 작업 복잡도를 크게 높였다.
통합된 감지-추론-제어 모델링 패러다임
현재 MLLM은 다중모달 인지 측면에서 뛰어난 성능을 보이지만, 로봇 제어와 같은 물리적 작업으로 직접 전환하기 어렵다. 주요 병목은 작업 목표 공간의 불일치에 있다. VeBrain은 이러한 한계를 돌파하여 로봇 제어를 두 개의 범용 MLLM 하위 작업으로 재구성했다.
첫 번째는 키포인트 검출(Keypoint Detection)로, 이미지를 입력으로 하여 2차원 목표 위치를 예측하고 운동 앵커 포인트로 사용한다. 두 번째는 기술 식별(Skill Recognition)로, 컨텍스트를 기반으로 “전진”, “집기”, “회전” 등의 의미적 동작을 생성한다.
이러한 언어화된 모델링 방식을 통해 VeBrain의 제어 작업은 이해 및 추론 작업과 통합된 입출력 공간을 공유할 수 있게 되어 다중작업 충돌과 재앙적 망각에 효과적으로 대항할 수 있다.

로봇 어댑터 모듈의 핵심 구성
또 다른 핵심 혁신은 로봇 어댑터 모듈이다. 이 모듈은 네 가지 주요 구성 요소로 이루어져 있다.
포인트 트래커(Point Tracker)는 사족 로봇이 운동 과정에서 시각 하의 키포인트를 실시간으로 업데이트한다. 운동 컨트롤러(Movement Controller)는 RGBD 카메라와 결합하여 깊이 정보를 획득하고 2D 좌표를 3D 제어 지시로 변환한다. 전략 실행기(Skill Executor)는 사전 훈련된 저수준 제어 전략(걷기, 집기 등)을 호출하여 작업 실행을 완료한다. 동적 인수인계(Dynamic Takeover)는 목표 손실이나 전략 실패 시 자동으로 언어 모델을 호출하여 재계획을 수행한다.
성능 테스트 결과 및 벤치마크 비교
VeBrain 팀은 13개의 다중모달 벤치마크와 5개의 공간 추론 벤치마크에서 성능을 테스트했다. 결과는 현재 최강 오픈소스 모델인 Qwen2.5-VL과 견줄 만한 다중모달 능력과 동일한 매개변수 수준에서 최적의 시각 공간 추론 능력을 실현했음을 보여준다.
구체적으로 MMVet(+5.6%), DocVQA(94.4점) 등 13개 기준에서 GPT-4o와 Qwen2.5-VL을 초월하여 77.1의 최고 정규화 평균 성능을 달성했다. 이는 더 강력한 다중모달 능력을 갖추고 있음을 의미한다.
3D 공간 이해 측면에서 3D 장면 질답(ScanQA CIDEr 101.5)과 물체 위치 지정(ScanRefer Acc@0.25 66.4%)에서 기록을 갱신했으며, 모든 작업에서 GPT4Scene-HDM을 초월하는 성과를 보였다. 특히 VSI 벤치마크 테스트에서 평균 점수는 모든 기존 MLLM을 능가했으며, Qwen2.5-VL-7B보다 +4.0% 높은 성능을 보였다.
실제 로봇 플랫폼에서의 검증
VeBrain의 범용성과 통용성을 증명하기 위해 연구팀은 사족 로봇과 로봇 팔을 실제 검증의 두 가지 실체로 선택했다. 사족 로봇, 특히 복잡한 장거리 작업에서 기존 VLA 모델과 MLLM 모델 대비 +50% 성공률 향상을 달성했다.
로봇 팔, 특히 장거리 작업에서도 VeBrain은 π0 모델 대비 현저한 개선을 보였다. 이러한 결과는 다양한 로봇 플랫폼에서 안정적이고 효과적인 제어 능력을 발휘할 수 있음을 입증한다.
소거 실험을 통해 VeBrain 팀은 VeBrain-600k 데이터셋의 풍부성과 필요성을 검증했다. 다중모달 이해 측면에서 양호한 성능을 보이는 기존 MLLM들이 시각 공간 추론과 로봇 제어 측면에서는 부족한 성능을 보였으며, “복잡한 찾기” 작업의 성공률은 0%에 불과했다. 반면 로봇 어댑터를 장착한 후 Qwen2.5-VL은 두 로봇 제어 작업에서 성공률이 명확히 향상되었다.
미래 전망과 의미
VeBrain의 등장은 구현 지능 분야에서 중대한 돌파구를 마련했다. 이 시스템은 “보기-사고-행동”의 인간과 같은 인지 과정을 로봇에게 부여하여 진정한 의미의 통용 인공지능 구현에 한 걸음 더 다가갔다.
특히 통합 모델링 패러다임은 향후 로봇 분야의 발전 방향을 제시한다. 감지, 추론, 제어 능력을 하나의 프레임워크로 통합함으로써 로봇이 더욱 복잡하고 동적인 환경에서 작업을 수행할 수 있게 되었다.
상하이인공지능연구소의 이번 성과는 중국의 AI 기술 발전과 글로벌 경쟁력을 보여주는 대표적인 사례로 평가된다. VeBrain 프로젝트의 오픈소스 정책을 통해 전 세계 연구자들이 이 기술을 활용하여 더욱 발전된 구현 지능 시스템을 개발할 수 있을 것으로 기대된다.
[논문 링크]
https://huggingface.co/papers/2506.00123/
[프로젝트 홈페이지]
https://internvl.github.io/blog/2025-05-26-VeBrain/
[추론 코드 및 모델 링크]
https://internvl.github.io/blog/2025-05-26-VeBrain/




