
중국 빅테크 기업 텐센트가 텍스트나 이미지 입력 만으로 상호작용 가능한 3D 가상 세계를 실시간으로 생성하는 ‘훈위안 월드모델(Tencent HY WorldPlay) 1.5’를 공개하고 오픈소스로 전격 공개했다. 이 모델은 장기적인 공간 기억 능력을 갖춰 일관성 있는 가상 환경을 생성하며, 사용자가 생성된 세계를 자유롭게 탐험할 수 있는 혁신적 기술로 평가 받고 있다.
텐센트 훈위안 팀이 12월 17일 공개한 월드모델 1.5는 단순히 가상 세계를 생성하는 것을 넘어, 사용자와의 실시간 상호작용을 지원하는 것이 핵심 특징이다. 사용자는 “녹슨 관람차가 있는 버려진 놀이공원, 잡초가 무성하고 향수를 자극하는 슬픈 분위기”와 같은 텍스트 명령어만 입력하면, 해당 설명에 부합하는 고품질의 게임 스타일 장면이 자동으로 생성된다. 생성된 공간은 시각적 일관성과 디테일이 뛰어나며, 필요한 모든 요소가 조화롭게 배치된다.
현재 이 모델은 텐센트 훈위안 3D 공식 웹사이트를 통해 체험 신청이 가능하며, GitHub와 Hugging Face를 통해 오픈소스로 공개되어 개발자들이 자유롭게 활용할 수 있다. AI 게임 개발, 영상 제작, 가상현실(VR), 그리고 구현화된 인공지능(Embodied AI) 훈련 등 다양한 분야에 적용될 수 있을 것으로 기대된다.

업계 최고 수준의 시각 품질과 기하학적 일관성
텐센트 훈위안 팀은 이번 월드모델 1.5를 “업계에서 가장 체계적이고 포괄적인 월드모델 프레임워크”라고 자평했다. 이 모델은 데이터 수집부터 훈련, 스트리밍 추론 배포까지 전체 과정을 아우르며, 재구성 메모리(Reconstructed Memory), 장기 컨텍스트 증류(Long Context Distillation), 3D 기반 자기회귀 확산 모델 강화학습(Reinforcement Learning) 등 혁신적인 알고리즘 모듈을 포함하고 있다.
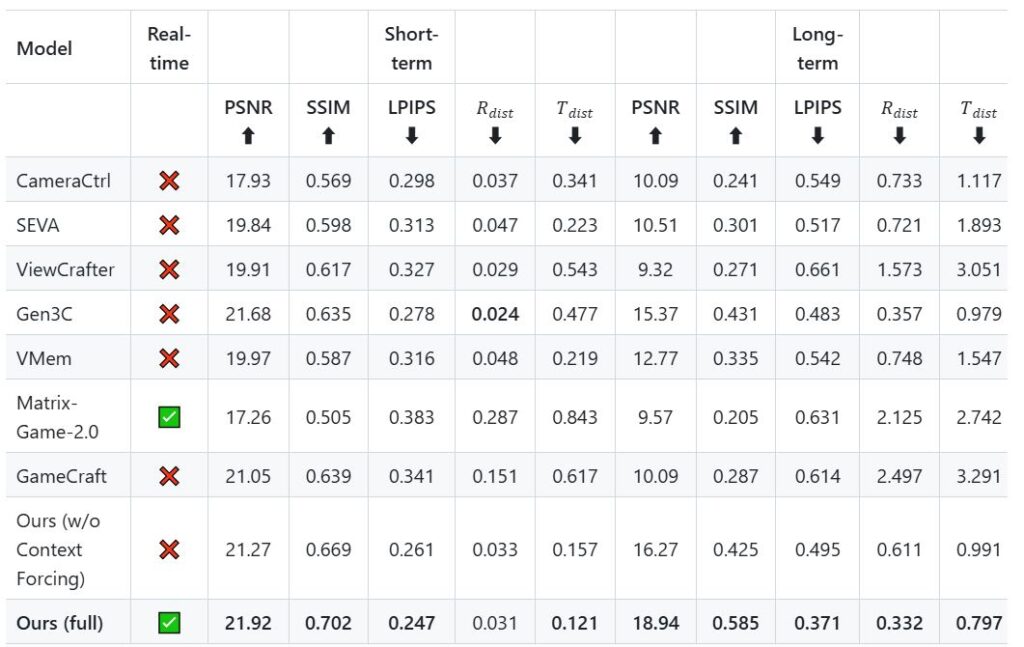
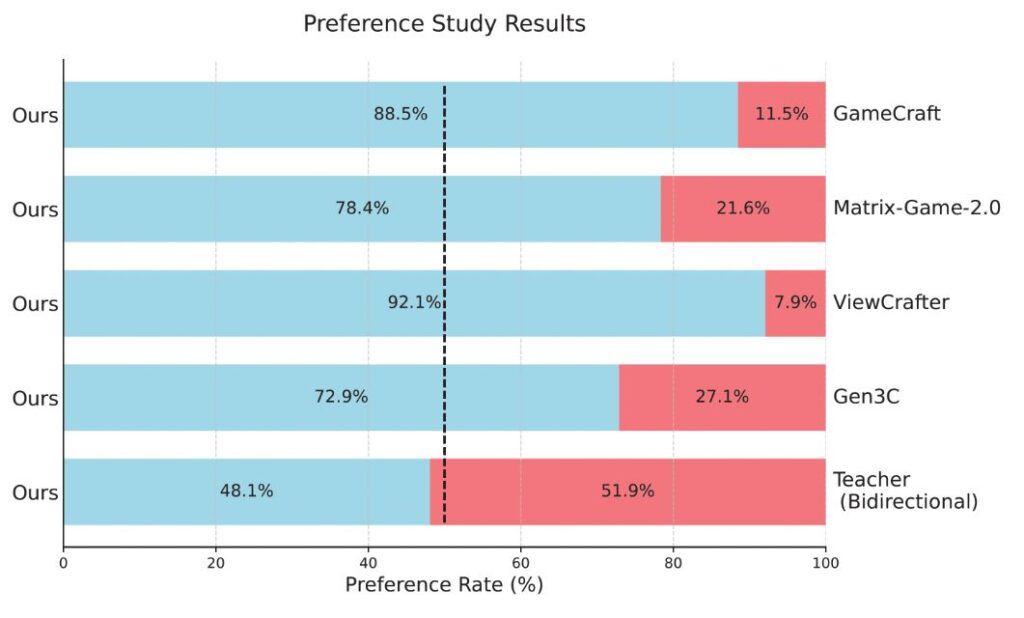
벤치마크 테스트 결과에 따르면, 훈위안 월드모델 1.5는 시각 품질과 기하학적 일관성 지표에서 모든 경쟁 모델을 압도했다. LPIPS, PSNR, SSIM 등 주요 시각 품질 지표에서 CameraCtrl, SEVA 등 기존 모델들을 크게 앞섰으며, 카메라 제어 정확도의 회전 거리 지표에서만 Gen3C와 ViewCrafter 두 모델에 약간 뒤처지는 수준이다. 특히 실시간 생성 능력, 장기 일관성, 광범위한 시야 예측 등에서 타 모델 대비 명확한 우위를 점하고 있다.
기존 모델들과 비교했을 때, 메모리 메커니즘이 없는 동작 제어 확산 모델(CameraCtrl, SEVA, ViewCrafter, Matrix-Game 2.0, GameCraft)과 메모리 메커니즘이 있는 모델(Gen3C, VMem) 모두를 능가하는 성능을 보였다. 특히 장기 시나리오에서 모든 지표가 경쟁 모델을 초월했으며, 이는 다른 모델들이 오차 누적으로 인해 제어 정확도가 크게 떨어지는 것과 대조적이다.
텍스트·이미지 입력으로 다양한 시점의 세계 생성
훈위안 월드모델 1.5는 텍스트 명령어 입력 뿐만 아니라 이미지와 텍스트를 함께 입력 받아 1인칭 시점과 3인칭 시점의 장면을 모두 생성할 수 있다. 사용자는 키보드, 마우스 또는 게임 컨트롤러를 사용해 가상 카메라의 이동과 회전을 자유롭게 조작할 수 있다.
1인칭 시점은 가상 카메라가 직접 보여주는 화면으로, 카메라가 움직이면 화면이 그에 따라 변화한다. 공식 데모 영상에서 1인칭 시점 장면은 카메라가 상하좌우로 회전할 때도 안정적이며 사람의 시각적 경험과 일치하는 자연스러운 움직임을 보여준다.

3인칭 시점은 가상 카메라 앞에 캐릭터가 추가되어, 사용자가 마우스와 키보드로 캐릭터를 조작하면 캐릭터의 움직임에 따라 화면이 변화한다. 주목할 점은 공식 데모 영상이 매우 정교하게 제작되어 캐릭터가 걸을 때 카메라가 미세하게 흔들리는 효과까지 구현했다는 것이다. 이는 게임이나 영화에서 흔히 볼 수 있는 자연스러운 카메라 워크를 재현한 것으로, 몰입감을 크게 높인다.

훈위안 월드모델 1.5는 다양한 스타일의 장면 생성을 지원한다. 생성 사례를 보면 화면 안정성과 스타일 일관성이 뛰어난 것을 확인할 수 있다. 또한 연기 효과나 폭발과 같은 특정 이벤트 트리거 기능도 지원하여, 동적인 장면 연출이 가능하다.
2D 이미지 기반 3D 공간 재구성 기능
텐센트는 이번 월드모델 1.5에서 3D 재구성 기능도 함께 선보였다. 좁은 공간, 실내 장면, 개방된 야외 공간 등 다양한 환경에 대한 재구성 사례를 공개했다. 생성 결과를 보면, 이 모델이 2D 이미지를 기반으로 자동으로 정보를 보완하여 비교적 정돈된 3D 장면을 재구성할 수 있음을 알 수 있다.
이는 Google의 DreamFusion이나 Meta의 3D 생성 기술과 유사한 접근 방식으로, 2D에서 3D로의 변환 과정에서 누락된 정보를 AI가 추론하여 채워 넣는 기술이다. 특히 메타버스나 디지털 트윈(Digital Twin) 산업에서 실제 공간을 빠르게 가상 공간으로 전환해야 하는 수요가 증가하는 만큼, 이러한 기술의 발전은 산업 전반에 큰 파급력을 가질 수 있다.
WorldCompass 강화학습 프레임워크 도입
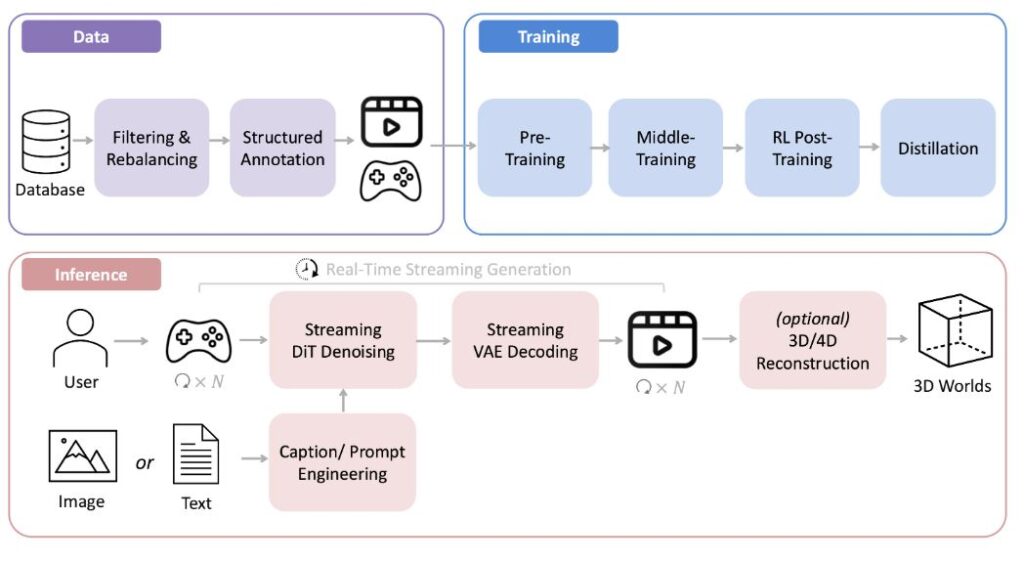
훈위안 월드모델 1.5의 핵심은 WorldPlay 자기회귀 확산 모델(Autoregressive Diffusion Model)이다. 이 모델은 이전 버전인 HY-World 1.0이 길고 오프라인 생성에 의존하며 실시간 상호작용이 부족했던 한계를 극복했다. 초당 24프레임의 속도로 고품질 장시간 비디오를 매끄럽게 생성할 수 있다.
이 모델은 사전 훈련(Pre-training), 지속 훈련(Continual Training), 자기회귀 비디오 모델 강화학습, 메모리를 갖춘 모델 증류(Distillation) 등 전체 훈련 프로세스를 아우르는 체계적이고 완전한 실시간 월드모델 훈련 프레임워크를 제공한다.
훈위안 월드모델 1.5는 32만 개의 비디오 클립을 포함하는 방대한 훈련 데이터 셋에 기반한다. 이 데이터는 AAA급 게임, 실제 3D 장면, 합성 4D 데이터, 자연 동적 비디오 등 다양한 소스에서 수집 되었다.
월드모델은 오랫동안 실시간 생성과 시스템 메모리 사용 사이의 균형을 맞추는 데 어려움을 겪어왔다. 이를 해결하기 위해 훈위안 월드모델 1.5는 네 가지 핵심 설계를 채택했다.
첫째, 이중 동작 표현법(Dual Action Representation)을 통해 시스템이 사용자의 키보드와 마우스 입력에 정확하게 반응하여 생성 콘텐츠를 실시간으로 제어할 수 있다.
둘째, 재구성 컨텍스트 메모리 메커니즘(Reconstructed Context Memory)을 통해 과거 프레임 정보를 동적으로 재구성하고 시간 재구성 전략과 결합하여 장기적인 기하학적 일관성을 유지한다. 이는 긴 비디오 생성에서 흔히 발생하는 메모리 감쇠 문제를 크게 완화한다.
셋째, WorldCompass 강화학습 프레임워크는 장기 자기회귀 비디오 모델을 위해 특별히 최적화된 새로운 후훈련(Post-training) 프레임워크로, 동작 추종 능력과 생성 화면의 시각적 품질을 직접적으로 향상시킨다. 강화학습 훈련이 없을 때 복잡한 상호작용 신호를 처리하면 모델이 시각적 열화를 보이지만, 강화학습 훈련을 거치면 동작 추종 정확도와 시각적 충실도가 현저히 개선되는 것으로 나타났다.
넷째, 상황 강제 증류법(Context-Forced Distillation)은 교사 모델과 학생 모델 사이의 메모리 컨텍스트를 정렬하여 생성 속도를 보장하면서도 모델이 장기 과거 정보를 활용하는 능력을 유지하게 함으로써 오차 누적을 효과적으로 억제한다.

이전 버전 대비 대폭 향상된 성능
텐센트 훈위안 팀은 올해 7월 훈위안 3D 월드모델 1.0을 출시했다. 이 모델은 텍스트 또는 단일 이미지 입력으로 렌더링 파이프라인과 호환되는 3D 장면을 생성할 수 있었다. 10월에는 월드모델 1.1이 출시되어 다중 뷰 또는 비디오를 한 번의 클릭으로 3D 세계로 전환할 수 있게 되었다.
이번 1.5 버전 업데이트는 훈위안 월드모델의 상호작용 능력에서 결정적인 진전을 의미한다. 이전 버전과 비교해 공간 기억 검색 능력이 크게 향상되었으며, 3D 장면 재구성, 장면 별 특정 이벤트 트리거 등 새로운 기능이 추가되어 단순히 몰입형 3D 세계를 생성하는 것을 넘어섰다.
사용자가 이미지나 세계를 설명하는 텍스트 프롬프트를 제공하면, 이 모델은 사용자가 입력한 동작 조건에 따라 다음 세그먼트(16개 비디오 프레임) 예측 작업을 수행하여 미래의 비디오 시퀀스를 생성한다. 각 세그먼트를 생성할 때 모델은 과거 세그먼트에서 컨텍스트 메모리를 동적으로 재구성하여 장기적인 시간적 일관성과 기하학적 일관성을 보장한다.
게임·VR·콘텐츠 제작 분야에 새로운 가능성
훈위안 월드모델 1.5는 AI 게임 개발, 영상 제작, 가상현실, 디지털 콘텐츠 제작 등 다양한 응용 분야에 새로운 도구와 가능성을 제공한다. 특히 게임 업계에서는 레벨 디자인이나 환경 제작에 소요되는 시간과 비용을 크게 절감할 수 있을 것으로 기대된다.
중국은 세계 최대 게임 시장이자 게임 개발 강국으로, 텐센트는 라이엇 게임즈(리그 오브 레전드), 에픽게임즈(언리얼 엔진) 등 글로벌 게임 기업에 대한 지분을 보유하고 있다. 이번 월드모델 기술은 텐센트가 보유한 게임 생태계 전반에 적용될 가능성이 높으며, 향후 글로벌 게임 산업에도 상당한 영향을 미칠 수 있다.
VR과 메타버스 분야에서도 활용도가 높다. Meta(구 Facebook)가 막대한 투자를 쏟아붓고 있는 메타버스 구축에 있어 가상 세계 생성 기술은 핵심 요소다. 텐센트의 월드모델 1.5가 오픈소스로 공개된 만큼, 중소 개발사나 스타트업도 이 기술을 활용해 자체 메타버스 플랫폼을 구축할 수 있는 기회가 열린 셈이다.
또한 구현체 인공지능(Embodied AI) 훈련에도 유용하다. 로봇이 실제 환경에서 학습하기 전에 가상 환경에서 시뮬레이션을 통해 훈련하는 것이 일반적인데, 훈위안 월드모델 1.5는 다양하고 현실감 있는 가상 훈련 환경을 빠르게 생성할 수 있어 로봇 학습의 효율성을 높일 수 있다.
글로벌 AI 경쟁에서 위상 강화
이번 텐센트의 월드모델 공개는 OpenAI의 Sora, Google의 Veo, Runway의 Gen-3 등 글로벌 빅테크들이 주도하는 비디오 생성 AI 경쟁에서 중국 기업의 기술력을 다시 한번 입증하는 사례다. 특히 실시간 상호작용과 장기 메모리 유지라는 측면에서 기존 모델들을 뛰어넘는 성능을 보여줬다는 평가도 있어 실제 업계에서의 활용 방향이 어떻게 진행될지 주목할 필요가 있다.
[온라인 체험 웹사이트]
https://3d.hunyuan.tencent.com/sceneTo3D?tab=worldplay
[GitHub]
https://github.com/Tencent-Hunyuan/HY-WorldPlay
[Hugging Face]
https://huggingface.co/tencent/HY-WorldPlay




